Petite histoire d’une énorme faille
 Imaginons que la quasi-totalité des PC, serveurs et smartphones sur la planète se retrouve soudainement exposée à des failles de sécurité, permettant à une variété d’acteurs allant de pays entiers aux pirates en herbe de voler des données sensibles. Imaginons ensuite que ces failles ne puissent pas être détectées par les antivirus parce qu’elles jouent sur le fonctionnement normal des processeurs. Cela ressemble au scénario d’un film de série B, mais malheureusement, c’est bel et bien la réalité à laquelle nous faisons face en ce début d’année.
Imaginons que la quasi-totalité des PC, serveurs et smartphones sur la planète se retrouve soudainement exposée à des failles de sécurité, permettant à une variété d’acteurs allant de pays entiers aux pirates en herbe de voler des données sensibles. Imaginons ensuite que ces failles ne puissent pas être détectées par les antivirus parce qu’elles jouent sur le fonctionnement normal des processeurs. Cela ressemble au scénario d’un film de série B, mais malheureusement, c’est bel et bien la réalité à laquelle nous faisons face en ce début d’année.
A l’issue d’un travail d’investigation, The Register a dévoilé les failles Meltdown et Spectre qui étaient jusque-là inconnues du grand public. Toutefois, les chercheurs du Project Zero de Google ainsi que deux autres équipes indépendantes avaient découvert ces mêmes failles quelques 200 jours auparavant. Comme c’est souvent le cas, les chercheurs ont laissé une période de répit aux entreprises directement concernées, parmi lesquelles Intel, AMD, IBM, Qualcomm et ARM, afin que des contre-mesures soient prises avant qu’ils ne révèlent ces failles au grand jour.
Ces mêmes entreprises, ainsi que les développeurs de Windows et Linux, ont travaillé ensemble durant des mois dans le plus grand secret. A défaut de coordination, la réponse initiale a été chaotique, suite à quoi nous avons assisté à une série d’erreurs tournant au comique, a fortiori quant on sait combien de temps les acteurs concernés ont eu pour se préparer.
Il faut cependant souligner le fait que ces entreprises ont dû combler des failles qui étaient présentes dans la conception même des logiciels et microprocesseurs depuis plus de dix ans : l’industrie devrait donc bénéficier d’un peu de bienveillance à ce titre. A vrai dire, presque tous les processeurs d’Intel depuis 1995 sont vulnérables. Le simple fait de penser au règlement des problèmes sans rompre l’interopérabilité entre composants et logiciels sur plusieurs dizaines d’années donne le tournis.
Quoi qu’il en soit, les correctifs sont censés avoir des conséquences en termes de performances. Etant donné que la situation commence à se stabiliser sur ce front après un mois de cacophonie, nous commençons nos mesures avec les jeux.
Le paysage confus des correctifs
Il existe deux failles, lesquelles se catégorisent en trois variantes : les deux premières correspondent à Spectre, tandis que la troisième est Meltdown. Nous savons que les processeurs d’Intel, ARM et Qualcomm sont vulnérables aux trois variantes, tandis que ceux d’AMD sont exclusivement concernés par Spectre.
Comme on peut le voir ci-dessous, une mise à jour du système d’exploitation protège contre les variantes 1 et 3. En revanche, la deuxième variante de Spectre qui est la plus vicieuse des trois nécessite une mise à jour du firmware/microcode au niveau de la carte mère en plus de correctifs du système d’exploitation.

Plutôt brouillonne, la réponse initiale de l’industrie s’est traduite par une série de correctifs prématurés pouvant causer des bugs. Ces correctifs n’étant pas livrés sous forme de pilotes, les fabricants de processeurs ne peuvent pas les déployer directement : ce sont ainsi Microsoft, Linux, divers OEM ainsi que les fabricants de carte mère qui les diffusent. La cadence à laquelle les correctifs sortent, le fait qu’il en existe plusieurs itérations rend la situation compliquée pour les utilisateurs avertis, sans même parler du grand public.
Les choses ont vraiment mal commencé : Intel a diffusé un correctif sous forme de microcode firmware/CPU qui causait des redémarrages, instabilités système et même un risque potentiel de données perdues/corrompues. Les partenaires d’Intel ont donc cessé la diffusion du firmware pour les cartes mères, puis Microsoft a désactivé le correctif logiciel censé protéger les machines de Spectre deuxième variante. Avant cela, Microsoft a diffusé un patch pour les configurations AMD qui en empêchait certaines de démarrer. La mise à jour a rapidement été retirée et le géant de Redmond a accusé AMD d’avoir fourni une documentation incorrecte. Un nouveau correctif a ensuite été proposé quelques semaines plus tard.
 A ce stade, Intel n’a pas de correctif au niveau du système d’exploitation ou de microcode pour protéger ses architectures de Spectre deuxième variante. A contrario, AMD dispose d’un patch logiciel, mais la firme texane n’a pas encore proposé de microcode. Malheureusement, les correctifs au niveau microcode sont ceux qui auront les plus lourdes conséquences en termes de performances : les résultats de cet article sont donc susceptibles d’évoluer.
A ce stade, Intel n’a pas de correctif au niveau du système d’exploitation ou de microcode pour protéger ses architectures de Spectre deuxième variante. A contrario, AMD dispose d’un patch logiciel, mais la firme texane n’a pas encore proposé de microcode. Malheureusement, les correctifs au niveau microcode sont ceux qui auront les plus lourdes conséquences en termes de performances : les résultats de cet article sont donc susceptibles d’évoluer.
Intel affirme que des correctifs seraient proposés pour ses processeurs conçus au cours des cinq dernières années avant de passer aux précédentes générations, mais de nombreuses voix estiment que l’on ne verra rien venir pour la plupart des anciens processeurs. Intel comme AMD ont déclaré que leurs prochaines générations de processeurs proposeraient des solutions au niveau architectural, mais nous n’en connaissons pas encore les détails.
Une chose est sûre : les correctifs actuels (Spectre deuxième variante en particulier) entraînent des baisses de performance dans certaines situations, a fortiori sur les anciennes générations de processeurs. Microsoft prédit que « certains » utilisateurs sous Windows 10 ayant des processeurs antérieurs à Broadwell constateront de nets ralentissements, tandis que « la plupart » des utilisateurs sous Windows 7 et 8.1 avec des processeurs équivalents noteront une baisse de performances.
La mesure de ces conséquences n’a pas été simple pour nous non plus. La nature changeante des correctifs rend les problèmes encore plus complexes : nous avons ainsi commencé plusieurs tests avant de voir le correctif modifié voir tout simplement retiré. Nous travaillons dur sur un prochain article qui traitera du domaine applicatif, de même qu’à l’élargissement du panel de processeurs afin d’inclure des modèles plus anciens. Pour le moment, nous avons des benchmarks en jeux ainsi qu’une bonne sélection de processeurs Ryzen, Kaby Lake et Coffee Lake à divers niveaux de prix. Voyons comment ces failles fonctionnent.
Utiliser l’inexploitable
Meltdown et Spectre sont des failles exploitables par canal auxiliaire, lesquelles sont incroyablement difficiles à contrer. Une attaque par canal auxiliaire consiste à observer les caractéristiques d’un ordinateur, qu’il s’agisse du timing de certaines opérations ou même des séquences de bruit et lumière, puis utiliser les informations obtenues pour voler des données.
Naturellement, tout commence par les données. Un CPU charge les données depuis la mémoire principale vers ses registres en demandant les contenus d’une adresse virtuelle, laquelle est à son tour associée à une adresse physique. Tout en remplissant cette requête, le processeur vérifie les autorisations de cette adresse, lesquelles indiquent si le processus est en mesure d’accéder à l’adresse mémoire ou bien si le noyau du système d’exploitation est le seul à pouvoir l’atteindre. Le système accorde ou refuse les accès en conséquence. L’industrie estimait que cette technique permettait de répartir la mémoire de manière sécurisée dans des zones protégées, d’où le fait que les systèmes d’exploitation projettent automatiquement l’intégralité du noyau dans l’espace virtuel adressable de l’agencement mémoire au sein de l’espace utilisateur. Ceci veut dire que le processeur peut essayer d’atteindre toutes les adresses virtuelles si nécessaire, mais il expose alors l’intégralité de ces adresses virtuelles à l’espace utilisateur.
Le problème vient de l’exécution spéculative, un aspect de l’exécution dans le désordre qui vise à exploiter les ressources processeur de manière optimale. Les cœurs de processeur en pipeline traitent les instructions par phases, comme la récupération (fetch) d’instructions, le décodage d’instructions, l’exécution, l’accès mémoire et l’écriture différée (write-back) dans le registre. Les processeurs actuels divisent chacune de ces phases fondamentales en une vingtaine étapes, ce qui facilite leur montée en fréquence.
Les processeurs s’appuient sur de nombreux pipelines permettant un traitement parallèle des instructions, d’où le fait que l’on voie ci-dessous quatre couleurs différentes passer en simultané par les quatre étapes. Les branches d’instructions peuvent conduire le pipeline à passer à une autre séquence d’instructions, ce qui peut engendrer un blocage : en attendant les commandes de la mémoire, ce dernier ne traite pas de données durant plusieurs cycles.
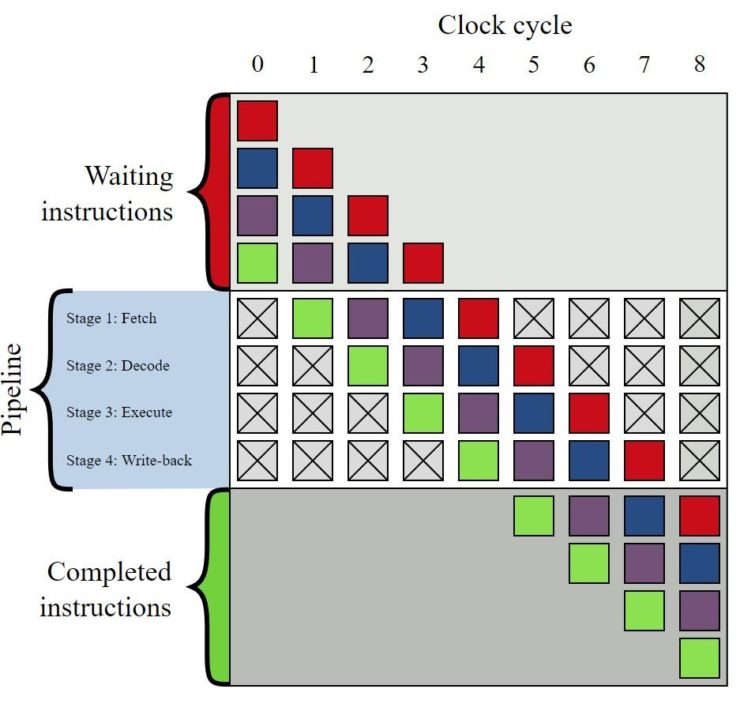
Afin d’éviter cette situation, l’unité de prédiction de branche parie sur la branche qui sera prise par le processeur, spéculation qui est donc faite avant que le processeur ne traite l’instruction. Le CPU récupère alors l’instruction pour la branche prédite et l’exécute. On supprime ainsi la latence induite par l’arrêt du pipeline compte tenu du branchement, de même que le fait de récupérer l’instruction suivante depuis la mémoire.
Suivant l’emplacement de l’adresse (cache L1, L2, L3, DRAM), la récupération des données depuis la mémoire nécessite entre une dizaine et une centaine de nanosecondes. Ce temps de traitement est long par rapport aux latences des cycles processeur, lesquelles sont inférieures à la nanoseconde. Le fait d’avoir des instructions déjà prêtes accélère donc considérablement les opérations. Le processeur exécute les instructions de manière prédictive, sans savoir si cela est nécessaire, tout en sachant que la plupart des opérations sont utiles vu que les prédicteurs de branchement ont souvent un taux de succès supérieur à 90 %. Dans le cas d’une mauvaise prédiction, le processeur rejette tout simplement l’instruction et libère le pipeline.
Les chercheurs de Google ont trouvé une petite faiblesse dans la manière dont le système gère les accès au cache mémoire durant les exécutions spéculatives. Les contrôles de sécurité normaux assurant une séparation entre l’espace utilisateur et la mémoire du noyau ne sont pas suffisamment rapides lorsque les exécutions spéculatives accèdent à la mémoire cache. En conséquence, le processeur peut momentanément chercher et traiter de manière spéculative des données à partir d’une mémoire cache à laquelle il ne devrait pas pouvoir accéder. Le système finit par refuser les accès et les données sont rejetées, mais ce processus est trop lent, au point de constituer une vulnérabilité exploitable. Meltdown abuse de la prédiction de branchement pour exécuter un code contre le cache tout en mesurant le temps nécessaire à cela. Ceci lui permet de déterminer quelles données sont gardées en mémoire comme on peut le voir dans la courte vidéo ci-dessous.
Dans le cas de Meltdown, un pirate peut lire mots de passe, clés de chiffrement ou autres données depuis la mémoire protégée. Ces données pourraient également servir à prendre le contrôle du système, rendant ainsi toutes autres formes de protection inutiles. Le principal problème pour les centres de données est que l’exploitation de cette faille permet à un programme résident sur l’une des machines virtuelles d’accéder à la mémoire d’une autre machine virtuelle. En clair, un pirate pourrait louer un espace sur un cloud public et récupérer les données d’autres machines virtuelles sur le même serveur.
Cette vulnérabilité est exploitable par l’intermédiaire de JavaScript : il suffirait de visiter un site web néfaste pour rendre sa configuration vulnérable. Si les développeurs de navigateurs ont mis à jour leurs produits de manière à réduire la granularité temporelle, rien n’empêche les pirates d’utiliser un code normal via un malware ou d’autres moyens pour lancer une attaque.
A ce stade, les patches OS pour Meltdown consistent à ajouter une couche de contrôles durant les accès aux adresses mémoire. Cela plombe la latence des appels système et ralentit donc les performances lorsque les programmes émettent des appels au noyau. En revanche, les programmes qui tendent à se maintenir au niveau de l’espace utilisateur sont moins sérieusement touchés. Notons par ailleurs que les processeurs Intel sortis après Broadwell bénéficient de PCID (Post-Context Identifiers), ce qui leur permet de limiter les dégâts par rapport aux architectures précédentes.
Spectre est encore plus vicieux dans la mesure où cette faille peut exploiter un éventail bien plus large des capacités du moteur de branchement prédictif, afin d’accéder à la mémoire noyau ou aux données d’autres programmes. Certains chercheurs affirment que la correction intégrale de cette faille pourrait nécessiter une révision fondamentale de toutes les architectures processeur. Il est donc possible qu’il faille vivre avec des déclinaisons de cette faille dans un avenir prévisible. Fort heureusement, il est particulièrement difficile d’exploiter cette faille vu les connaissances nécessaires au niveau du processeur et des programmes cible. Intel comme les autres acteurs ont commencé à proposer des correctifs pour les variantes actuelles de Spectre, mais il est possible que l’on assiste au jeu du chat et de la souris dès lors que de nouvelles évolutions de Spectre verront le jour.
Méthode de test
Notre méthodologie pour cet article est assez simple dans sa mise en œuvre. Pour commencer, nous avons lancé une série de benchmarks sur nos configurations Windows 10, après quoi nous avons installé les correctifs pertinents et répété les tests. Bien que le correctif OS pour Spectre deuxième variante tel que nous l’avons utilisé ait été supprimé depuis, il devrait illustrer le pire des cas de figure. Notons que nous n’avons pas utilisé de BIOS comprenant des contre-mesures spécifiques à Spectre vu qu’il n’y en avait pas lorsque les tests ont été effectués (les fabricants de carte mère les ayant supprimés). Nous reviendrons bien entendu avec des tests enrichis une fois que ces mises à jour seront disponibles pour de bon.
Tous les processeurs ont été testés à fréquence d’origine, parmi lesquels Core i3, Ryzen 3, Core i5, Ryzen 5, Core i7, Ryzen 7 et Pentium. Bien entendu, un processeur overclocké fera mieux. Comme toujours, nous désactivons la fonctionnalité Multicœur Turbo « améliorée » sur nos configurations.
Afin d’éviter la variance induite par GPU Boost en fonction des températures de notre GeForce GTX 1080, nous utilisons plusieurs occurrences de chaque benchmark en succession rapide. La valeur médiane est ensuite retenue, ce qui peut expliquer pourquoi à de nombreuses reprises les résultats avec/sans patch pourraient être inférieurs/supérieurs aux uns ou aux autres en fonctions des légères variations que nous voyons aujourd’hui.
| Configuration du test | |
|---|---|
| Composants | Intel LGA 1151 (Z370) Intel Core i3-8350K, Core i5-8600K, Core i7-8700K MSI Z370 Gaming Pro Carbon AC 2x 8 Go G.Skill RipJaws V DDR4-3200 @ 2666 AMD Socket AM4 AMD Ryzen 3 1300X, Ryzen 5 1600X, Ryzen 7 1800X MSI Z370 Xpower Gaming Titanium 2x 8 Go G.Skill RipJaws V DDR4-3200 @ 2667 Intel LGA 1151 (Z270) Intel Core i3-7350K, Core i5-7600K, Core i7-7700K, Pentium G4620 MSI Z270 Gaming M7 2x 8 Go G.Skill RipJaws V DDR4-3200 @ 2666 Communs aux trois configurations EVGA GeForce GTX 1080 FE SSD Samsung PM863 1 To SilverStone ST1500-TI 1500 Watts Windows 10 Creators Update version 1703, pre- et post-patch Corsair H115i |
VRMark et 3DMark
VRMark & 3DMark
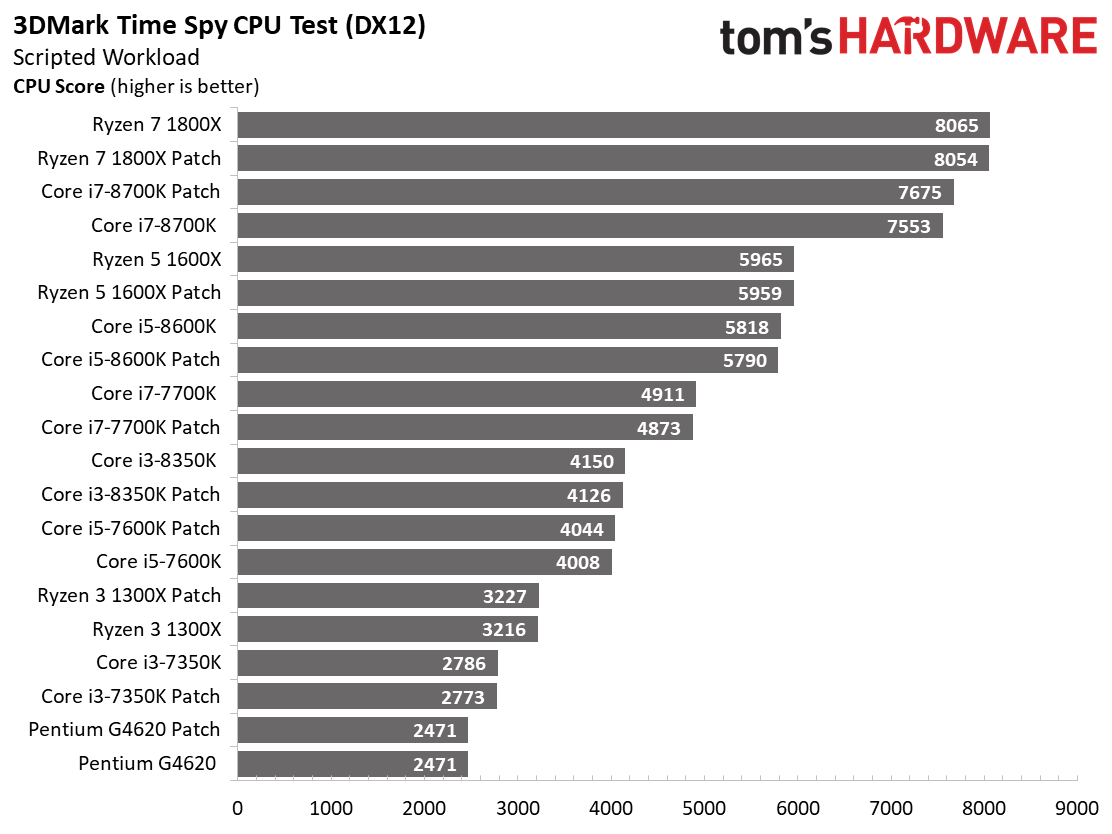
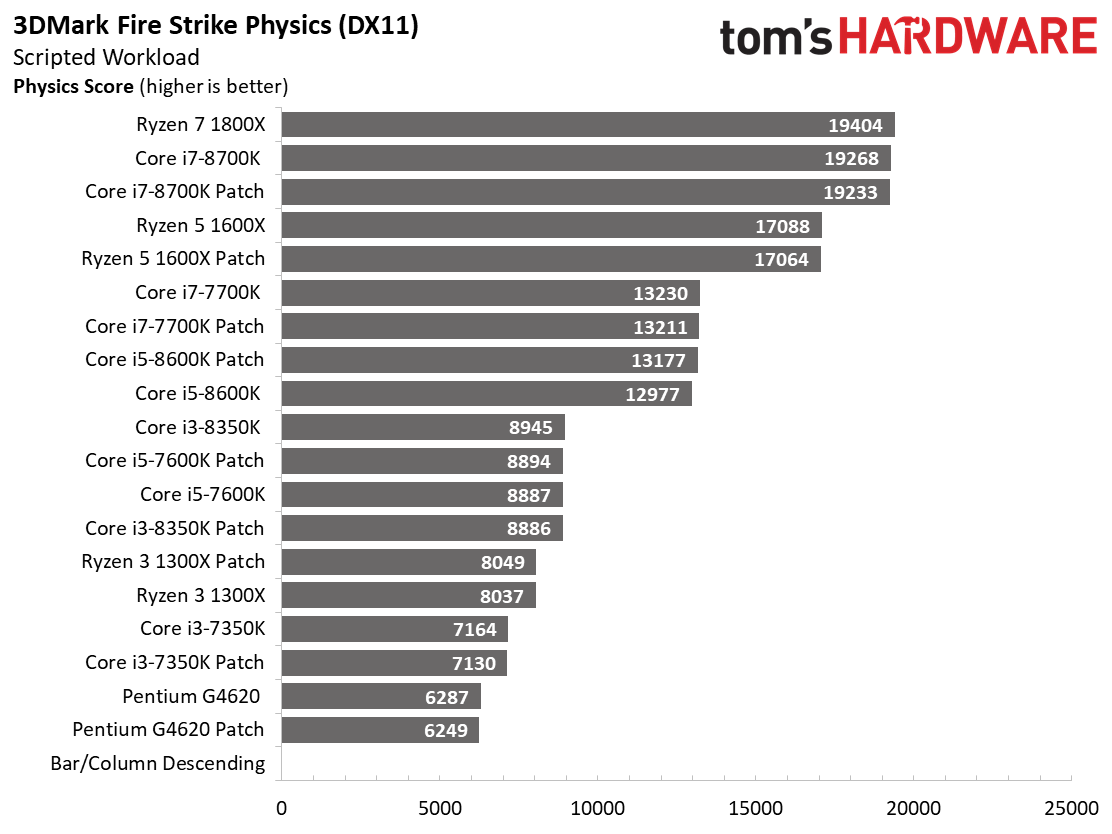
D’après Futuremark, les résultats varient de 3% maximum entre les boucles de test si l’on s’appuie sur les pratiques standard pour ce genre d’exercice, à savoir utiliser des configuration matérielles et logicielles similaires entre les différentes machines, laisser ces dernières entrer dans un état de repos et conduire les tests avec un environnement constant. Naturellement, certains sous-tests d’une suite (comme PCMark 10) peuvent faire ressortir des écarts allant au-delà des 3%, ce qui nous fait recourir aux moyennes. Notons que cela n’a pas été nécessaire avec ces benchmarks portés sur les jeux.
VRMark fait état de répercussions minimes des patchs sur tout notre panel de processeurs. Les systèmes d’exploitation patchés sont même parfois plus performants, mais les écarts sont compris dans la marge d’erreur de 3%. En clair, cette avance ne tient qu’à la variabilité des résultats d’une boucle de test à la suivante.
Les tests processeur DX11 et DX12 répondent à l’augmentation du nombre de cœurs disponibles et au potentiel de parallélisme qui en découle. Très franchement, il n’y a pas grand-chose à voir : s’il existe quelques écarts entre les configurations avant/après patch, ils n’ont rien de significatif.
AotS: Escalation et Dawn of War III
Ashes of the Singularity: Escalation
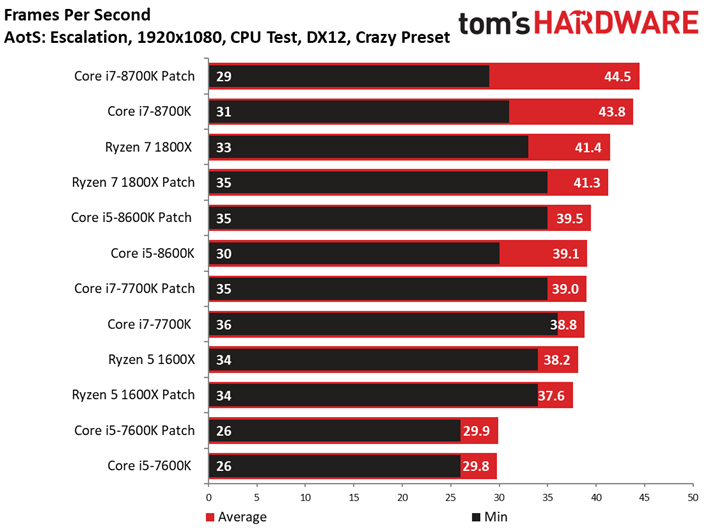
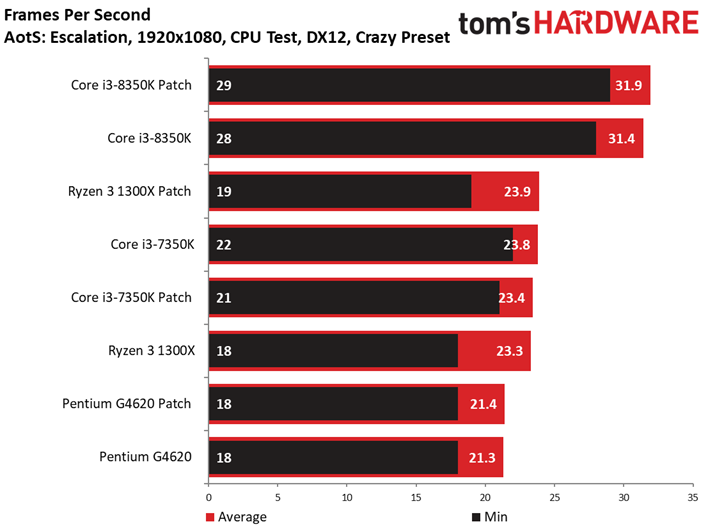
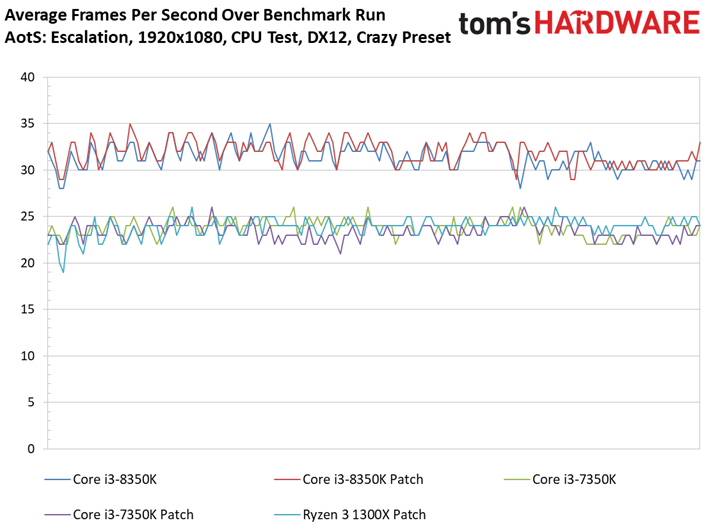
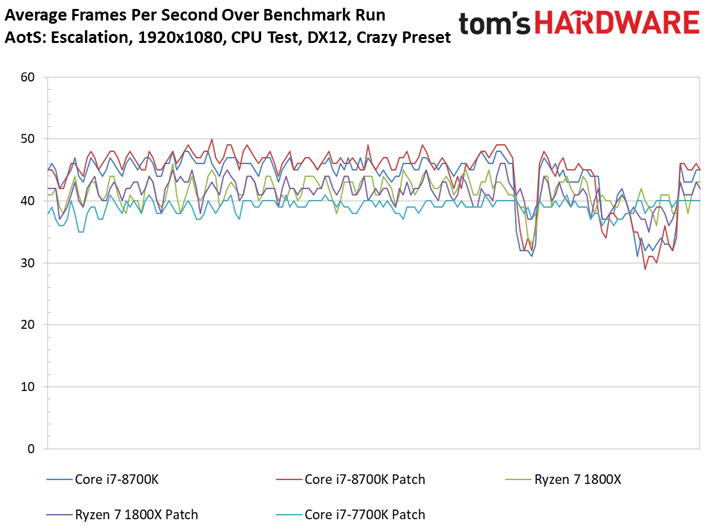
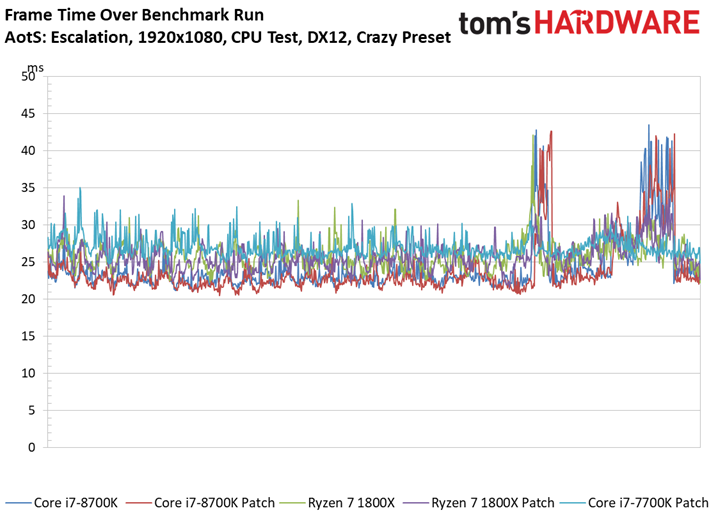
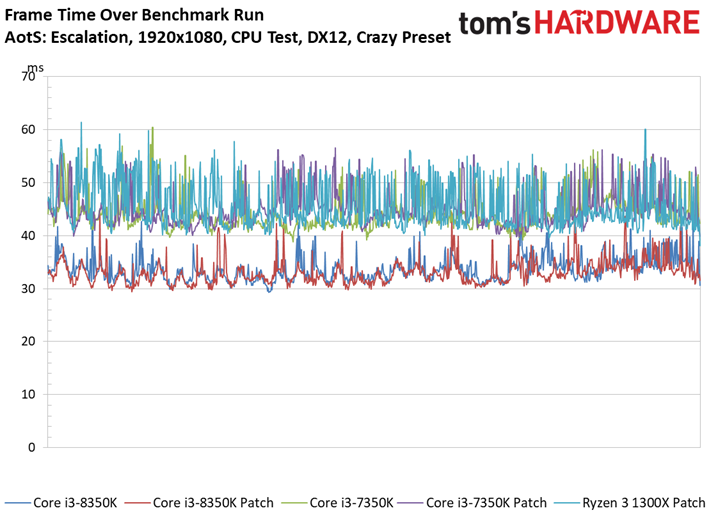
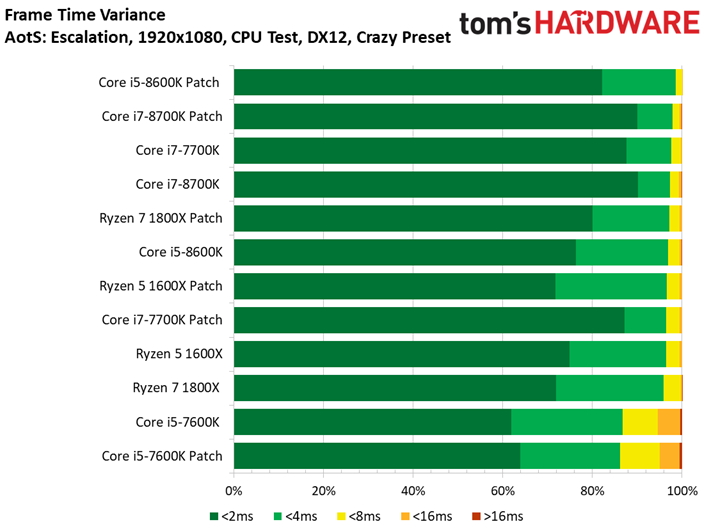
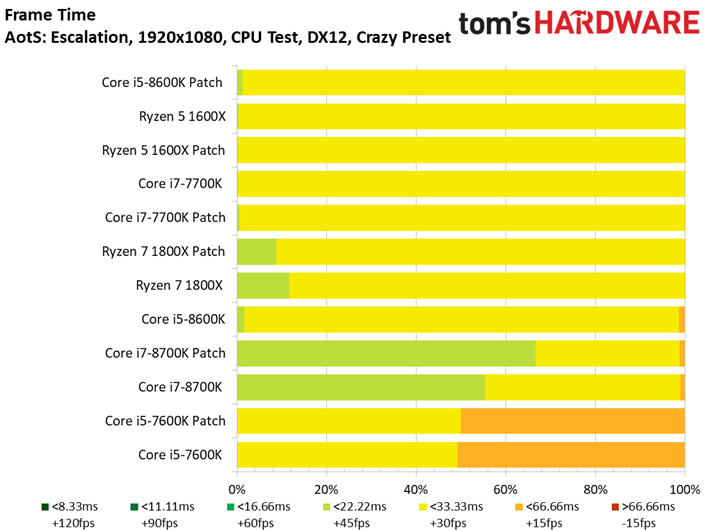
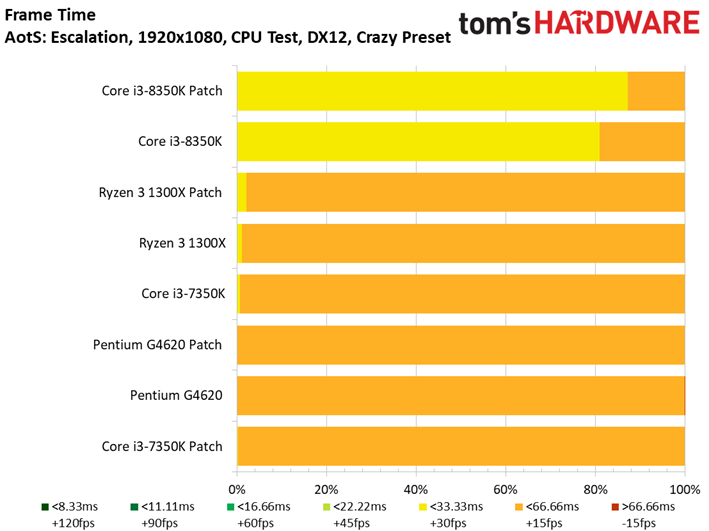
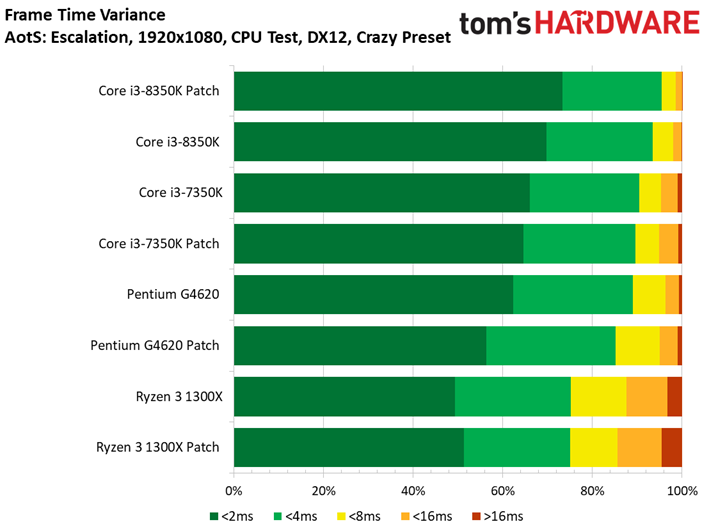
Ashes of the Singularity : Escalation voit lui aussi ses performances s’échelonner en fonction des ressources disponibles, signe que la carte graphique ne constitue pas un goulet d’étranglement. On peut observer des écarts mineurs entre les configurations avec/sans patch : le Core i7-8700K surpasse ainsi son équivalent sans patch, mais le delta de 1,6 % reste compris dans la marge d’erreur. On ne relève pas non plus d’écarts significatifs au niveau des performances dans le temps ou de la variance inter-images.
Précisons que nous avons séparé les résultats en deux groupes vu le nombre de tests conduits : les résultats inhérents aux Core i3, Ryzen 3 et Pentium sont donc distincts de ceux concernant les Core i7 et Ryzen 7.
Warhammer 40,000: Dawn of War III
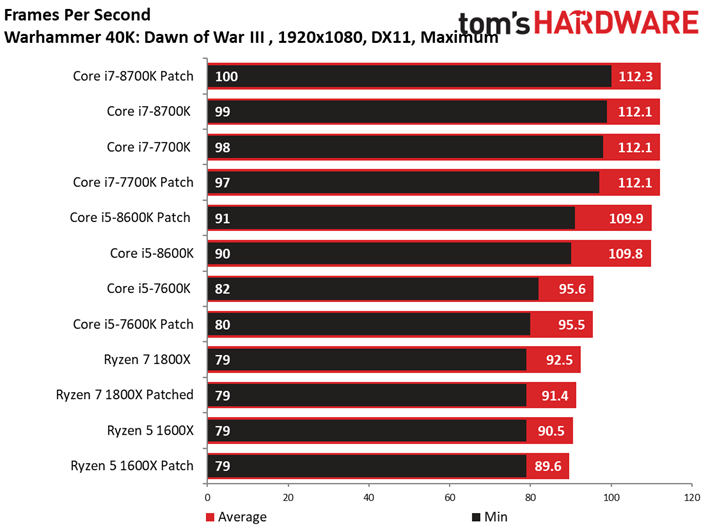
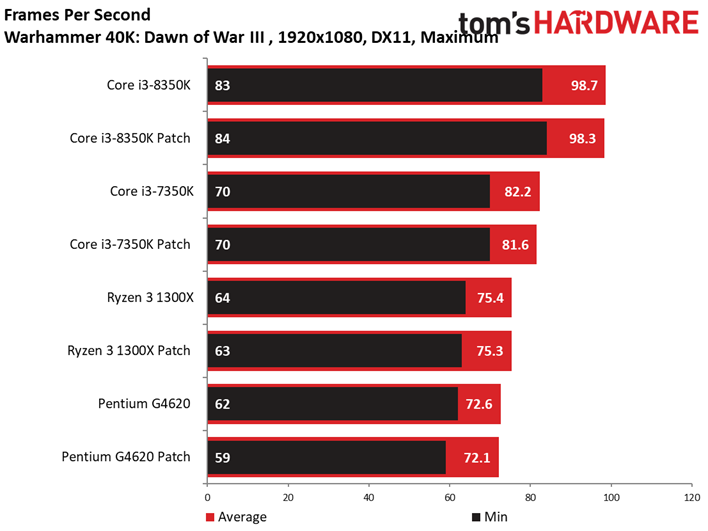
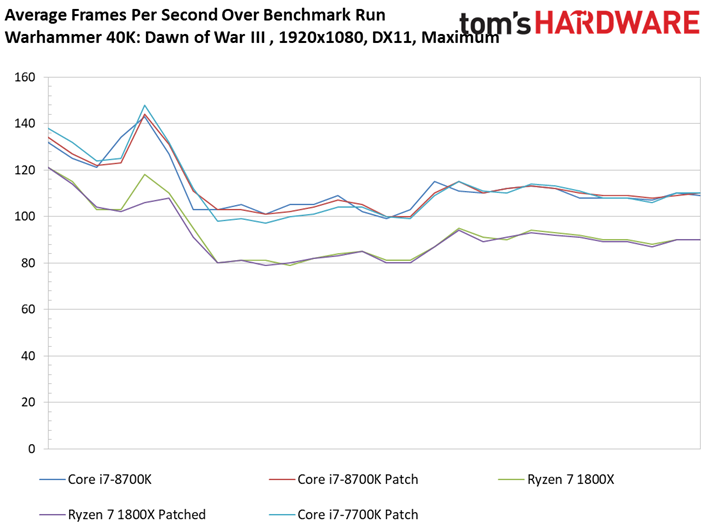
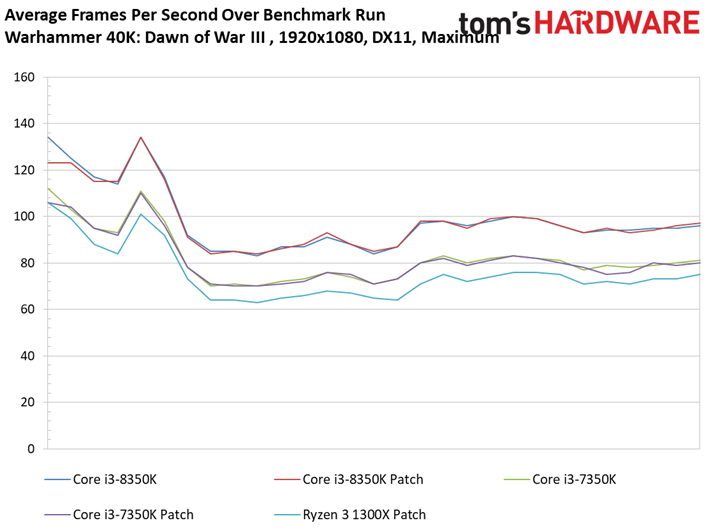
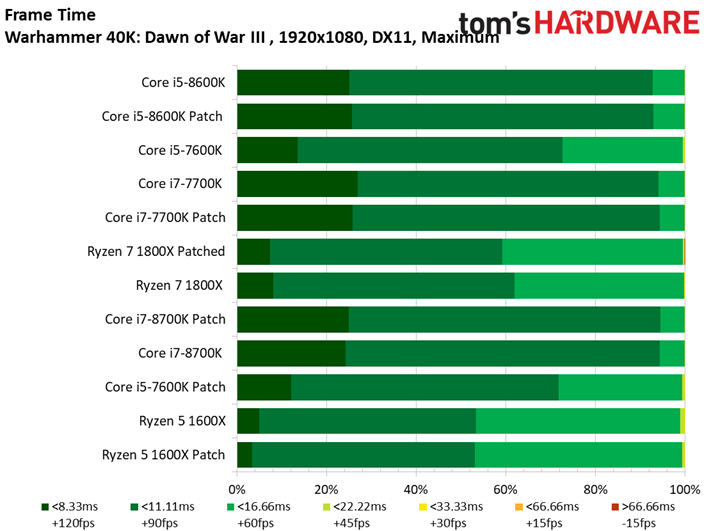
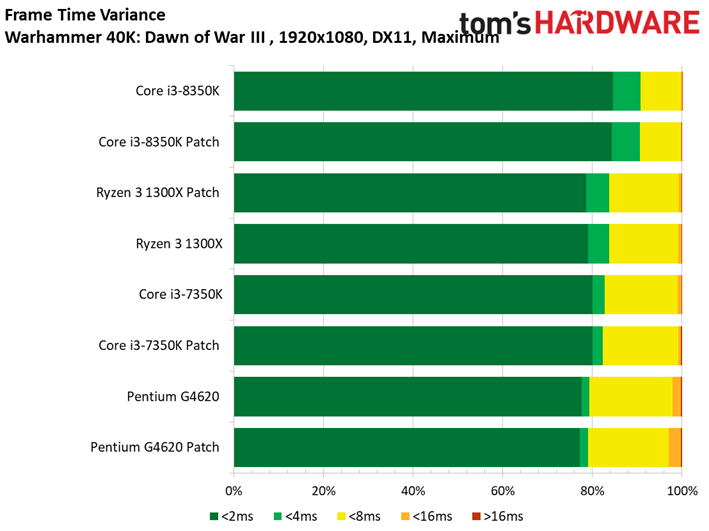
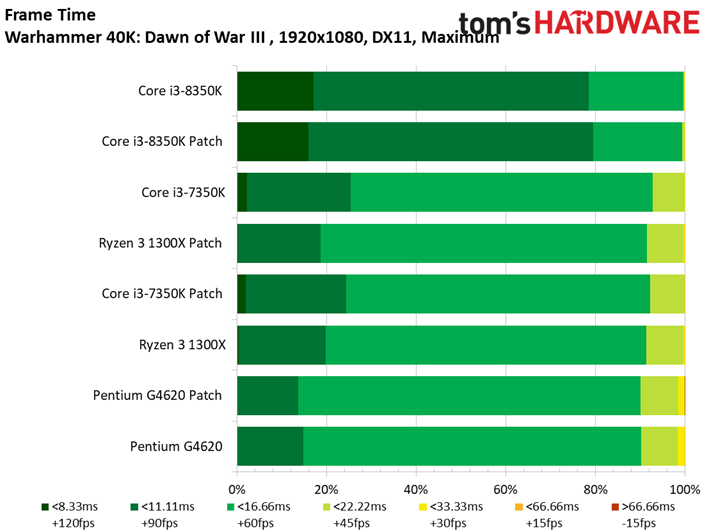
Dawn of War n’est pas plus affecté par les patchs, bien que l’on note pour la première fois un écart supérieur à une image par seconde : le Ryzen 7 1800X abandonne 1,1 ips après patch, soit 1,2 % d’écart. Encore une fois, le résultat est anecdotique.
Civilisation VI, CPU et GPU
Civilization VI – test AI

Le benchmark Civilization VI AI mesure les performances CPU sur ce qui est un jeu de stratégie en tour par tour, tendant à favoriser une association entre nombre de cœurs physiques, fréquences et débit en IPC. Les résultats sont contrastés : la moitié des processeurs sont plus lents avec patch, mais cinq autres s’avèrent plus rapides. Ceci étant dit, l’écart le plus conséquent se limite à 0,15 seconde, ce qui ne donne donc pas d’intérêt au tableau dans sa globalité.
Civilization VI – test GPU
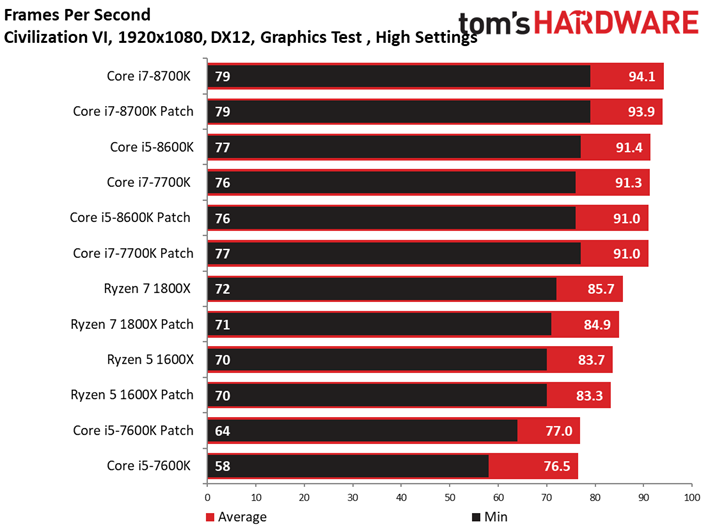
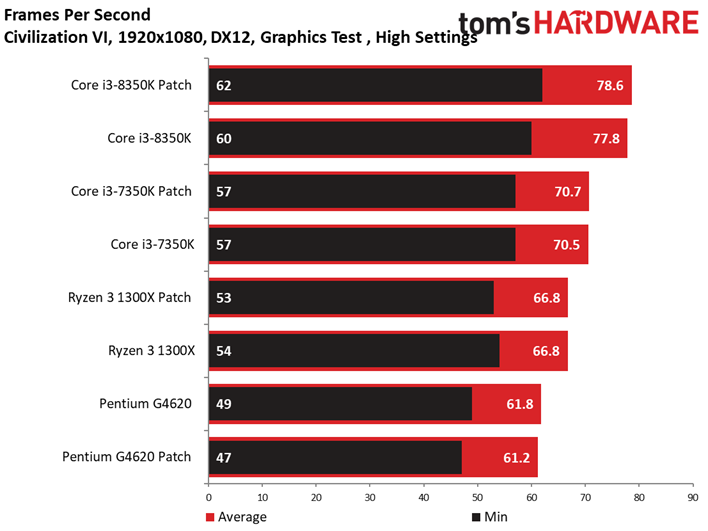
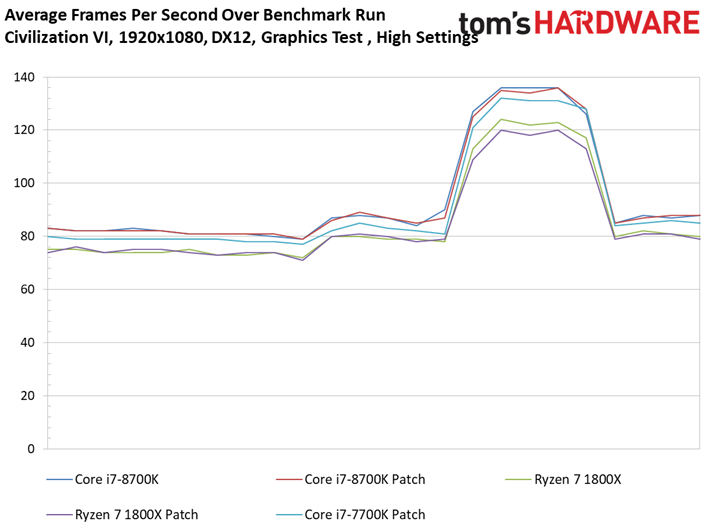
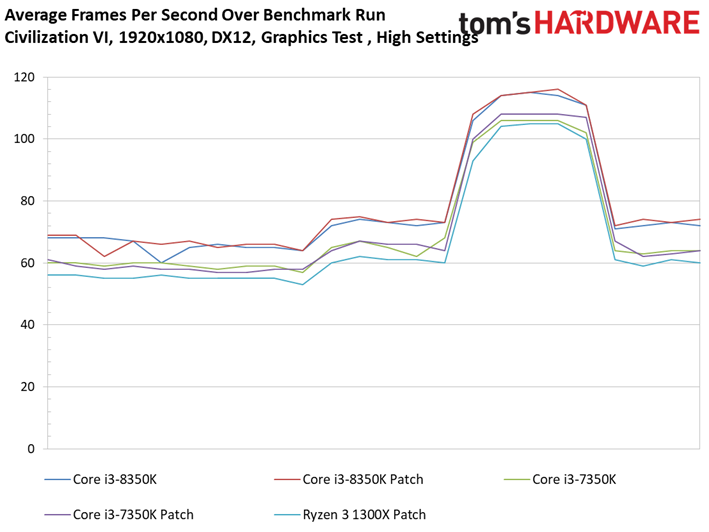
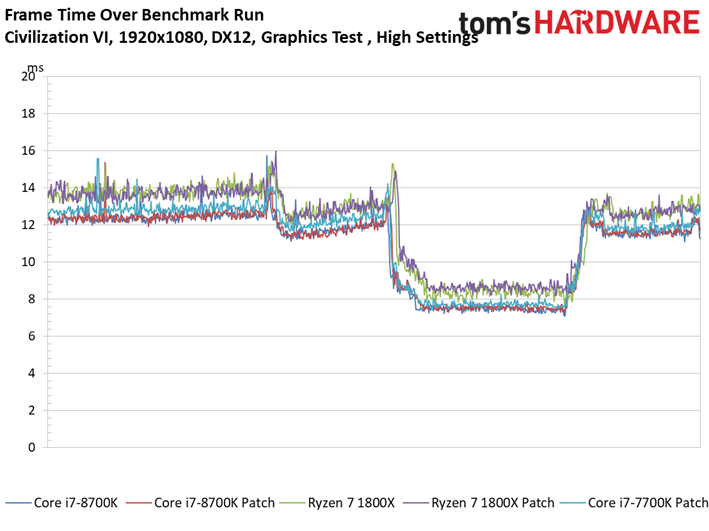
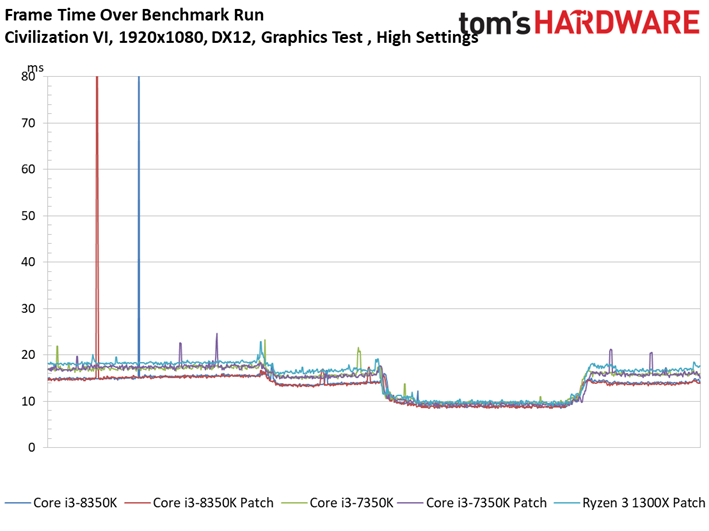
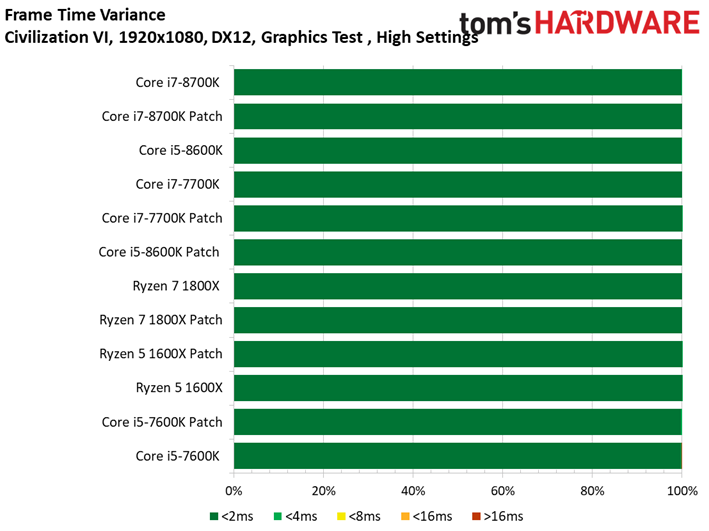
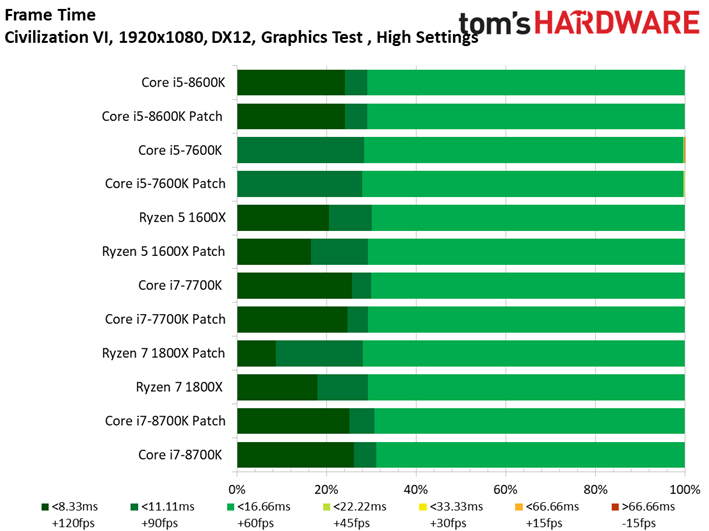
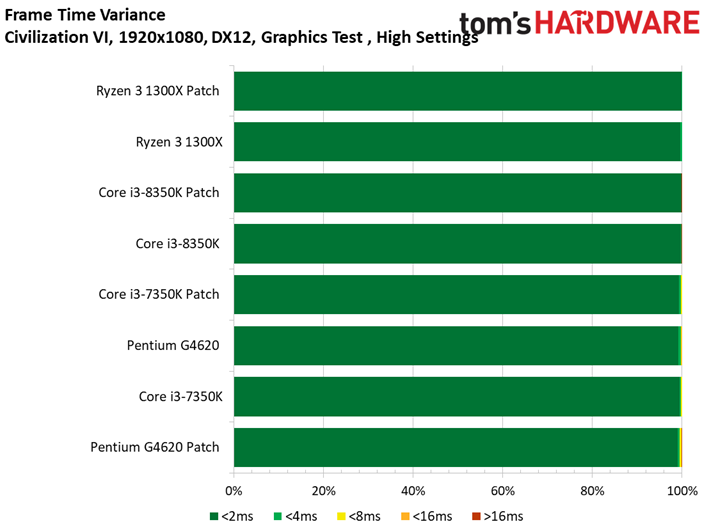
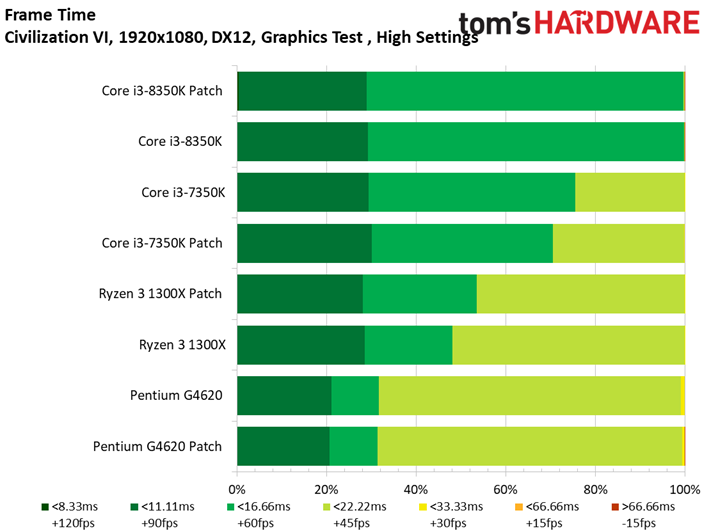
Les résultats du test GPU de Civilization VI ne sont pas plus surprenants que ce que l’on a pu voir précédemment avec Ashes of the Singularity : Escalation. Les patchs n’ont pas ou peu de conséquences sur les performances, les configurations protégées sont parfois devant, parfois derrière les configurations vulnérables. Le Ryzen 7 1800X est le processeur affichant la plus grande variance, à savoir 0,8 ips en moyenne (soit moins d’un pourcent). Même le benchmark illustrant les performances au 99ème centile ne distingue pas les configurations avec et sans patch.
Far Cry Primal et GTA V
Far Cry Primal
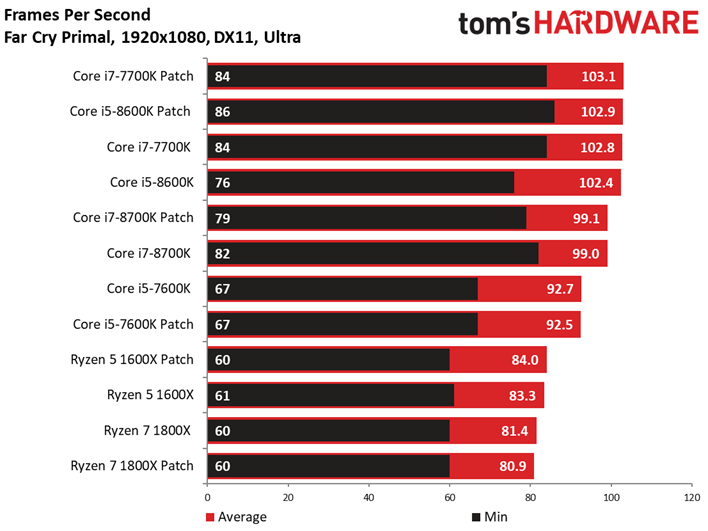
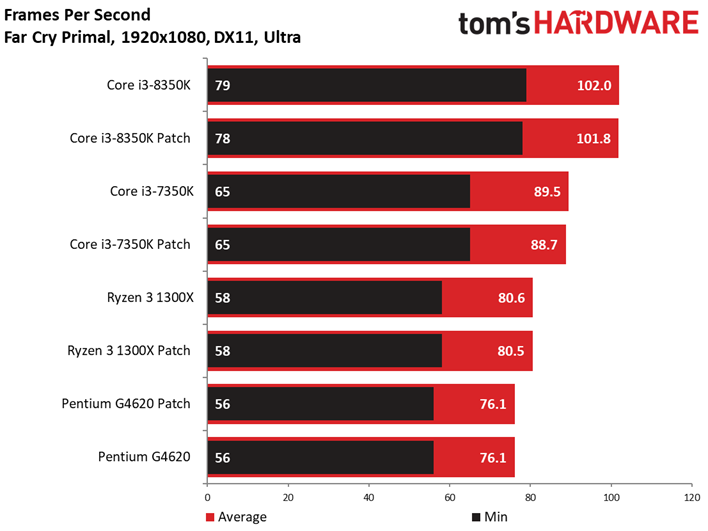
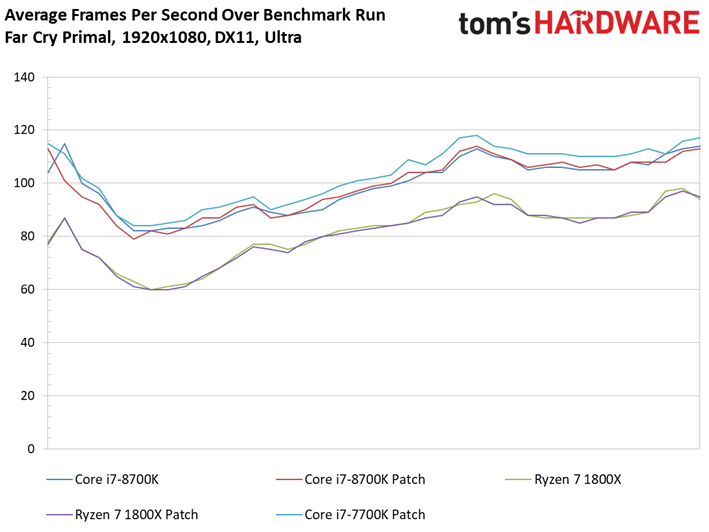
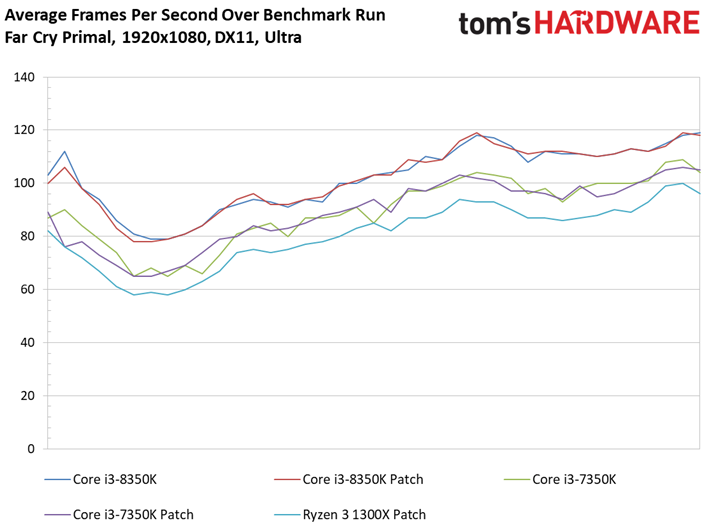
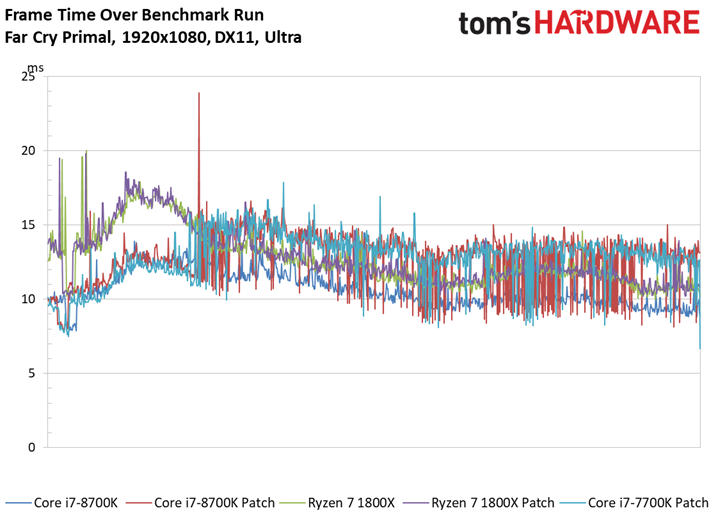
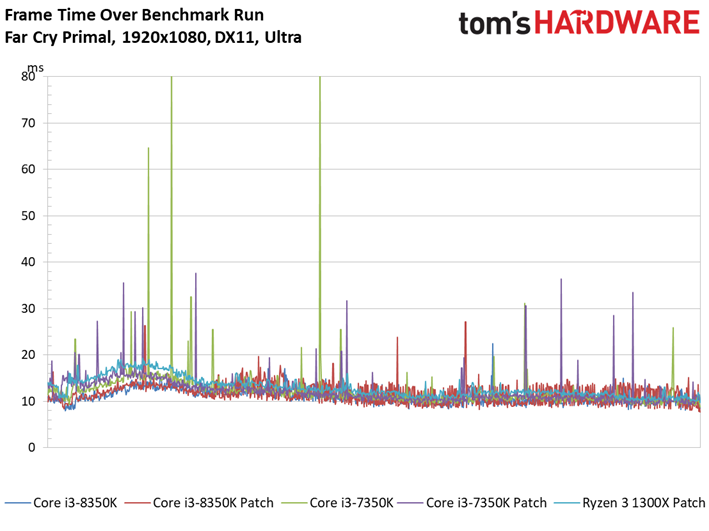
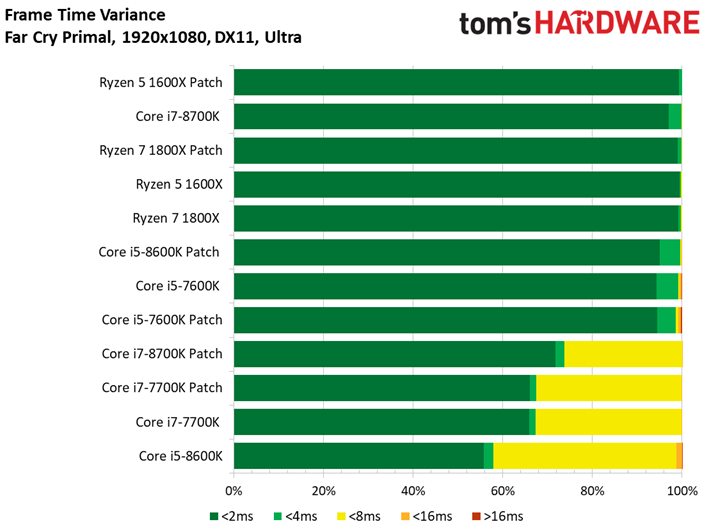
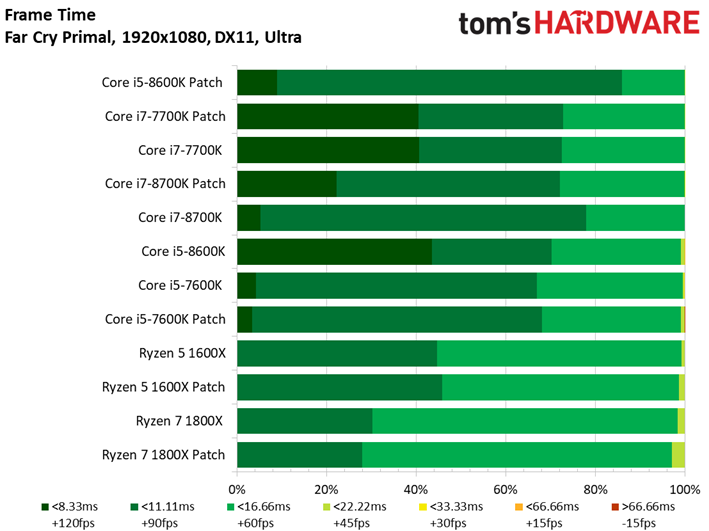
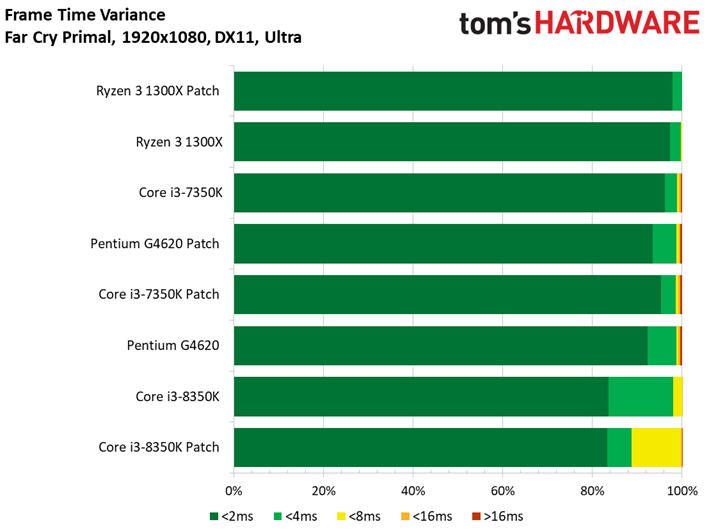
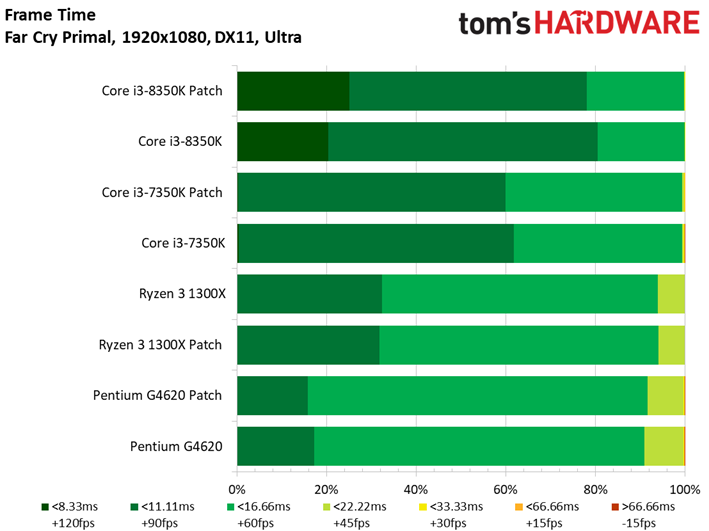
Le Dunia Engine 2 de Far Cry Primal apprécie tout particulièrement les fréquences élevées ainsi que le débit en IPC. Ajoutons à cela qu’il semble préférer la désactivation du multithreading, d’où le fait que les Core i5 soient particulièrement compétitifs ici.
Si l’on voit un peu plus de latence inter-images sur certains processeurs par rapport aux précédents benchmarks, tantôt ce sont les processeurs sans patch qui prennent les devants, tantôt l’inverse : une fois encore, les écarts doivent donc être attribués à la marge d’erreur.
Nos tests ayant généralement tendance à faire figurer des composants compris dans une fourchette de prix cohérente, les valeurs plancher et plafond ne sont pas aussi prononcées. Cet article nous donne une bonne occasion de voir comment différentes classes de processeurs se situent entre les autres : l’écart moyen entre un Intel Pentium G4560 et un Core i7-7700K est par exemple de 27 fps avec notre GeForce GTX 1080.
Grand Theft Auto V
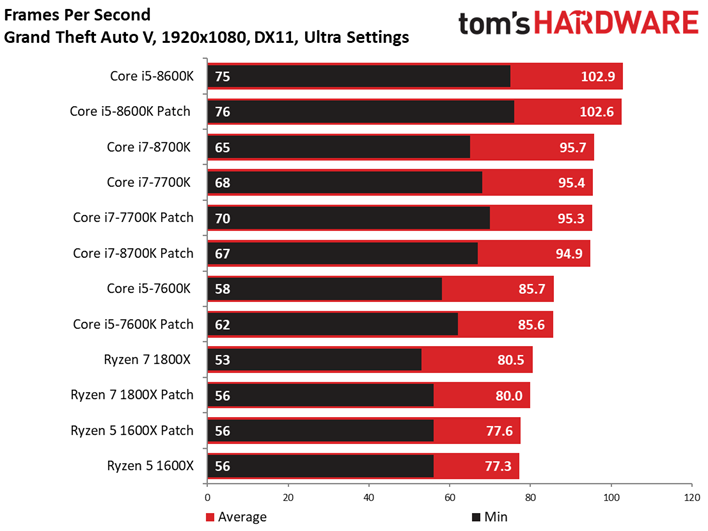
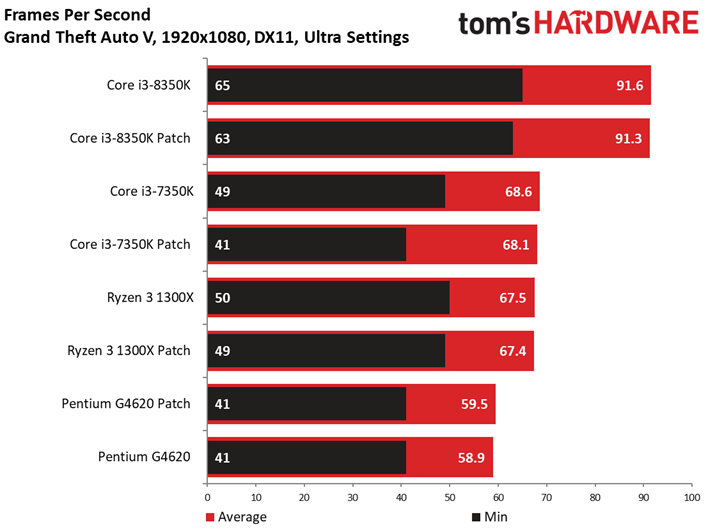
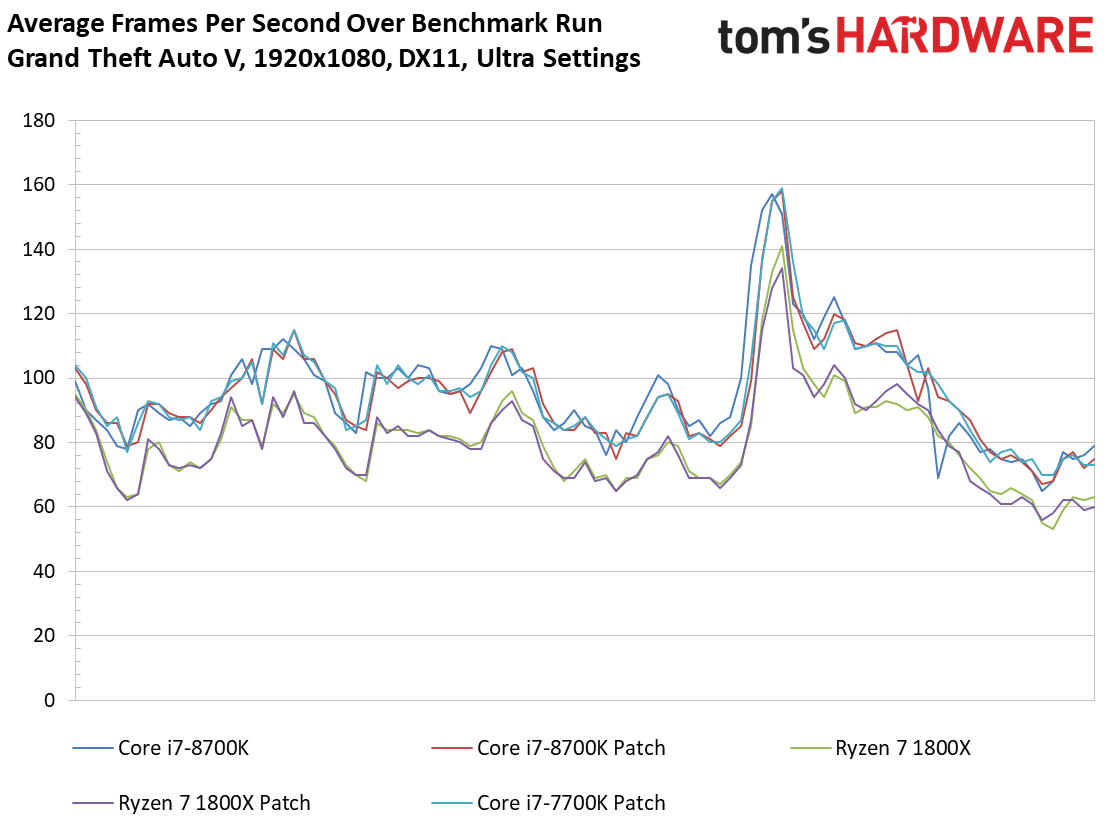
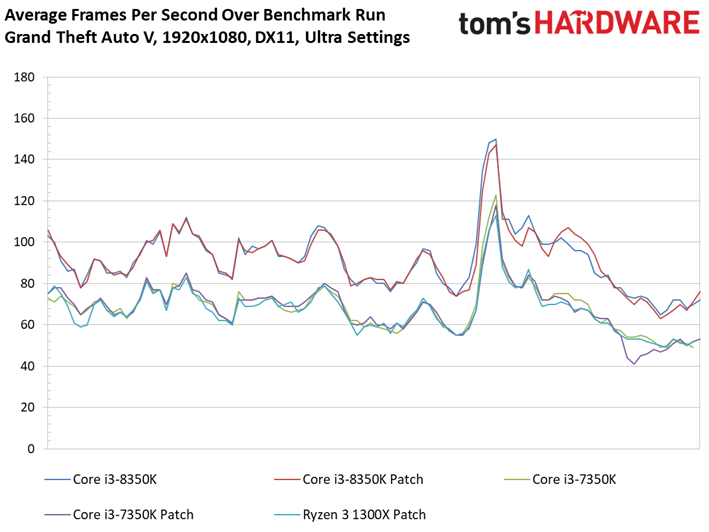
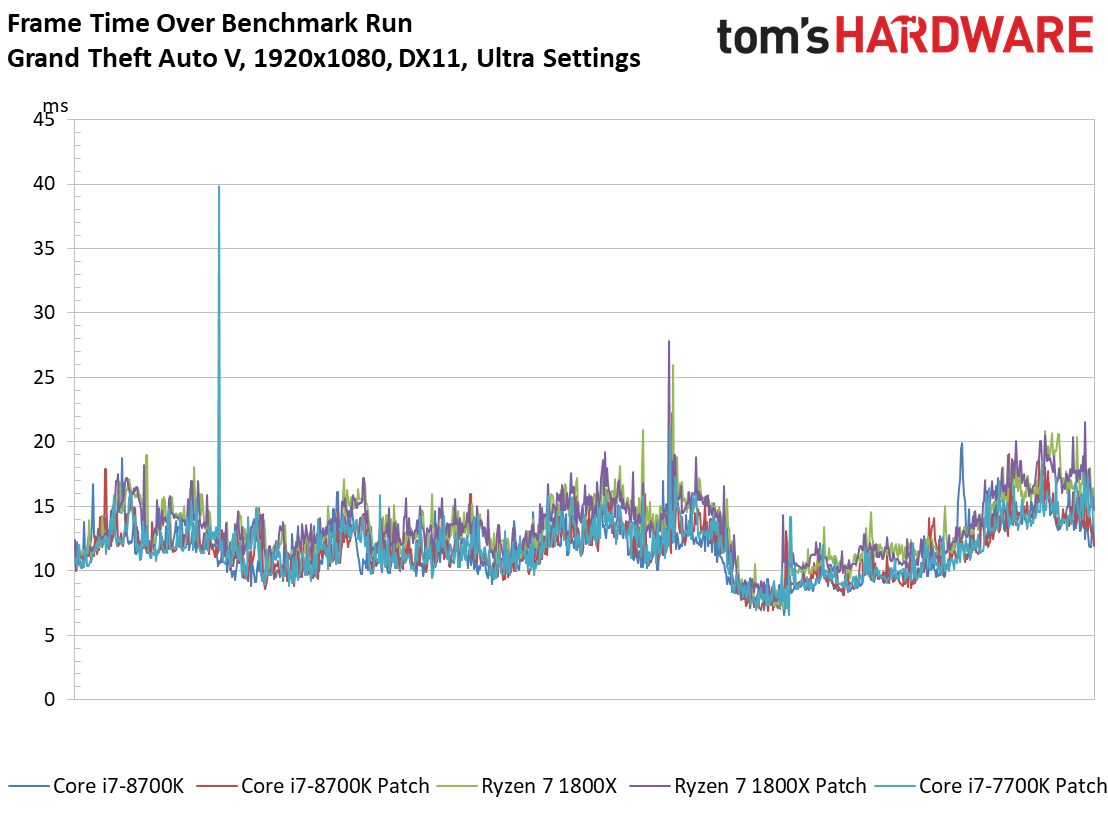
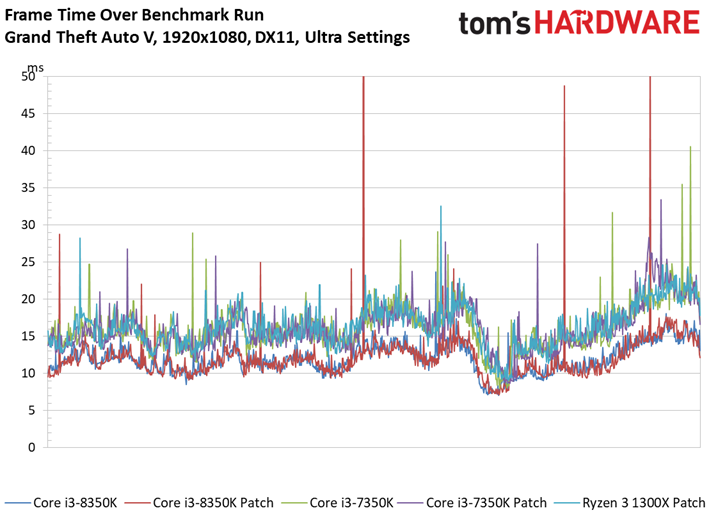
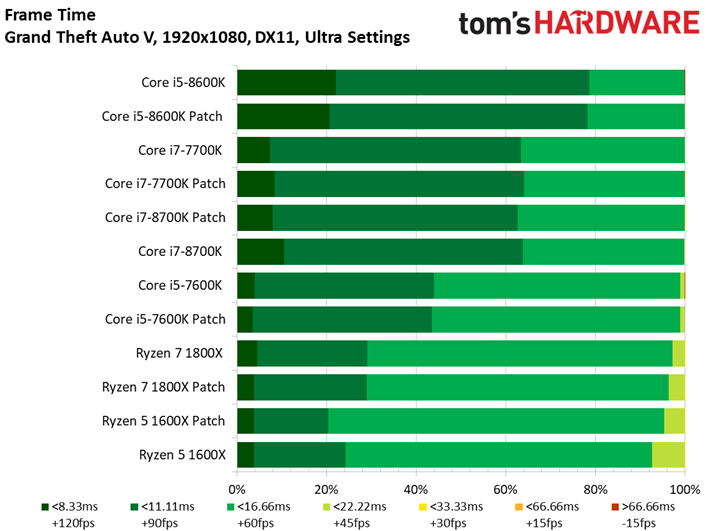
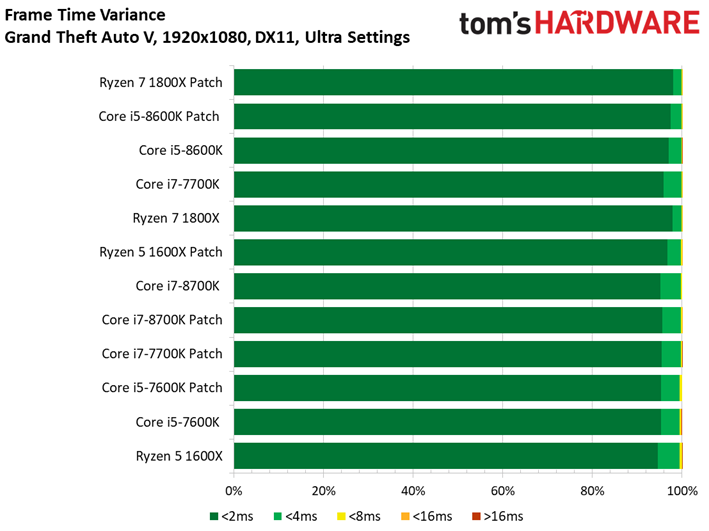
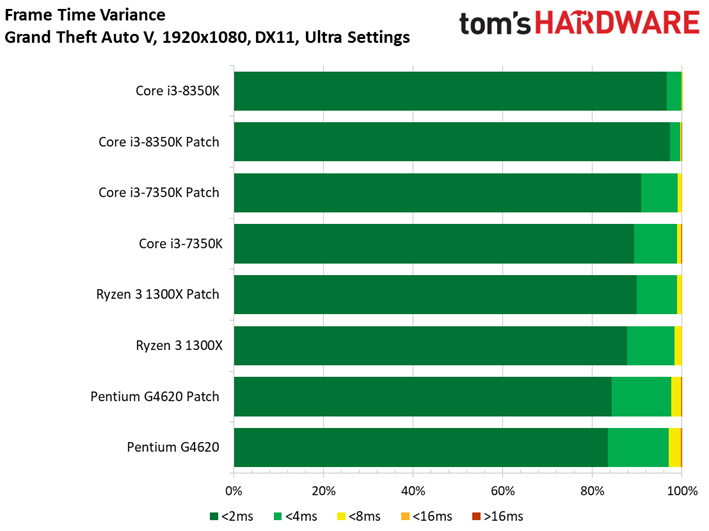
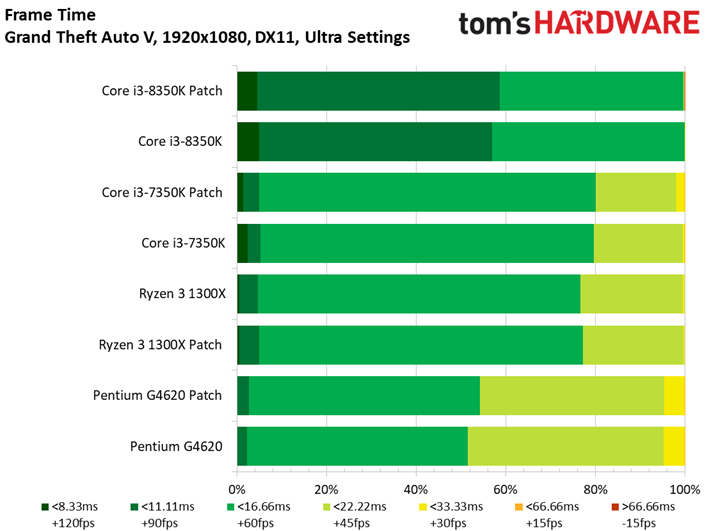
Le benchmark de Grand Theft Auto V fait lui aussi ressortir des écarts assez faibles entre configurations avec et sans patch, de même que des conséquences négligeables sur la latence inter-images. Si l’on remarque quelques points de mesure aberrants dans le cas du Core i3-8350K, il convient de noter que ces points se produisent aussi bien après patch que sans patch. On relève par ailleurs 42 ips au 99ème centile pour le Core i3-7350K après patch, contre 47 ips sans. Il s’agit d’un des écarts les plus importants parmi toutes les mesures effectuées pour cet article.
Hitman et Shadow of War
Hitman (2016)
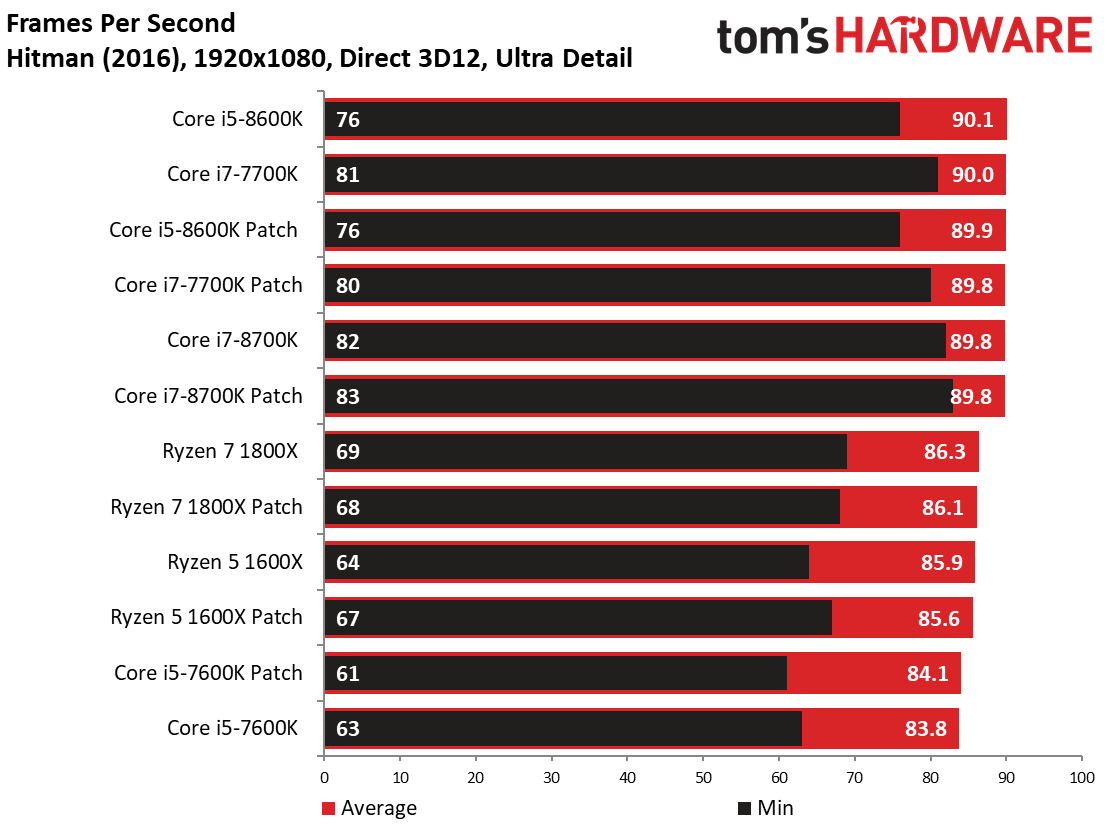
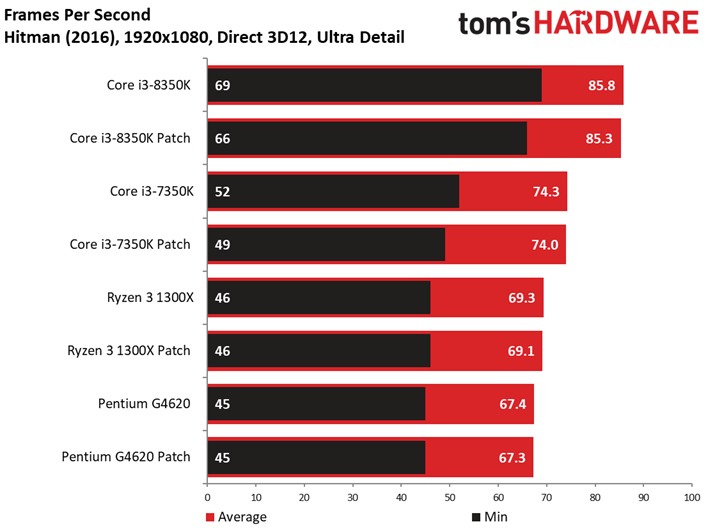
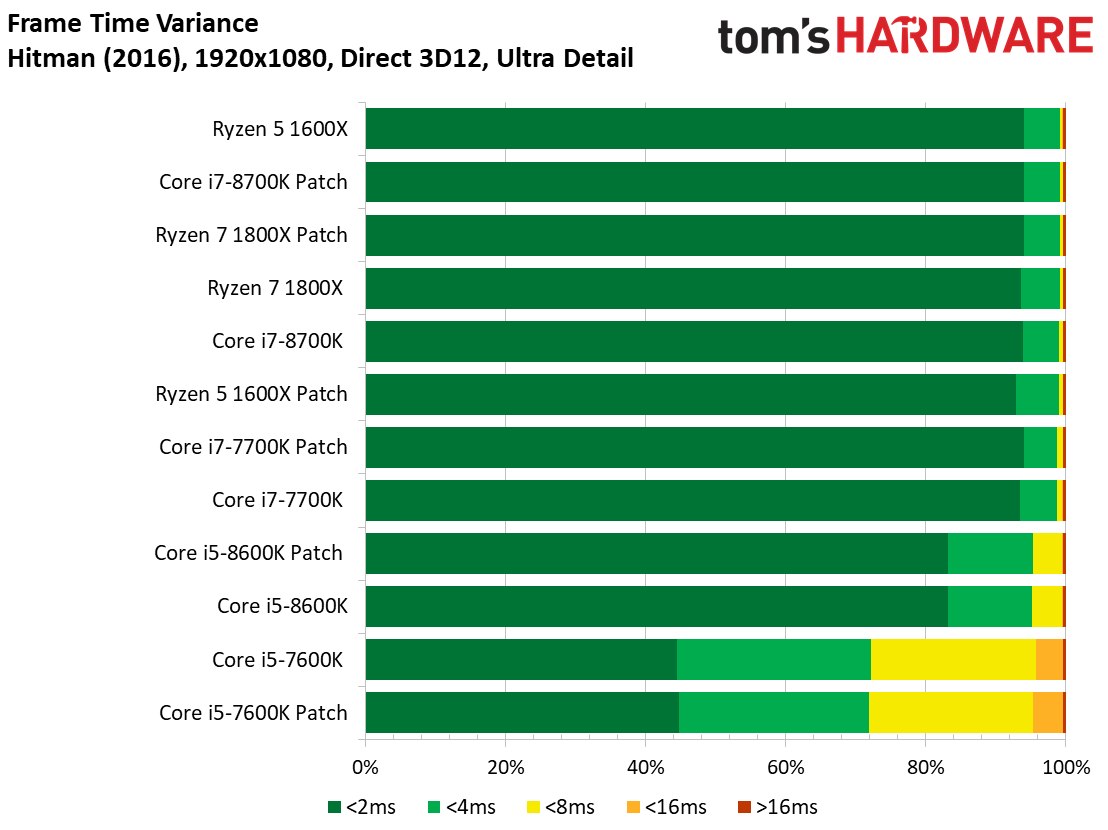
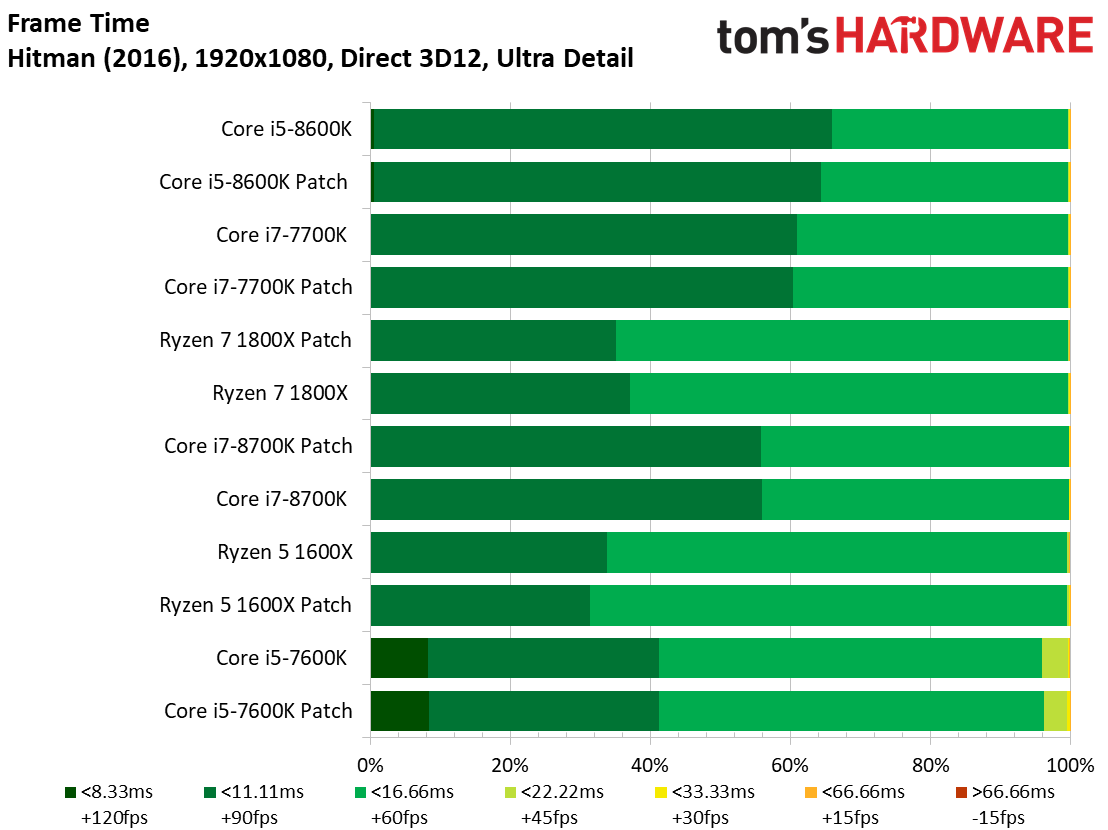
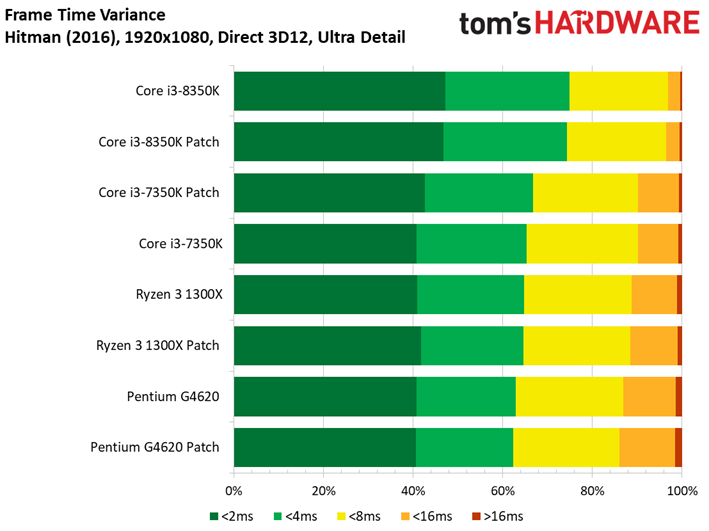
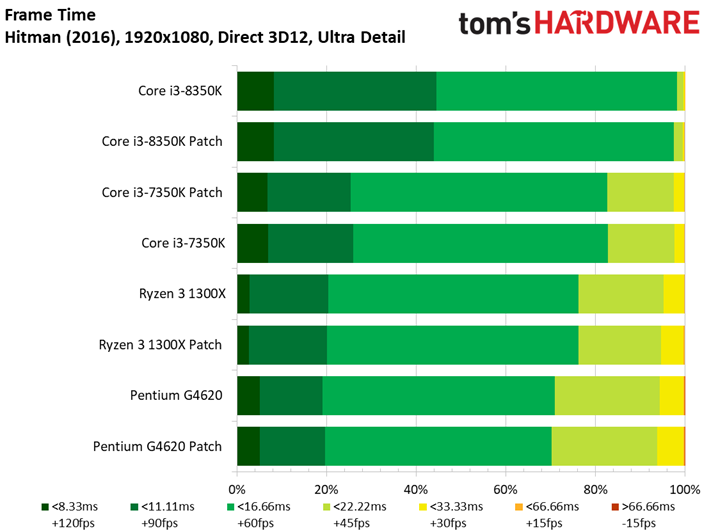
Hitman étant un jeu particulièrement limité par les ressources graphiques, il n’y a pas d’écarts ou presque entre les Core i7 et Core i5.
Middle-earth: Shadow of War
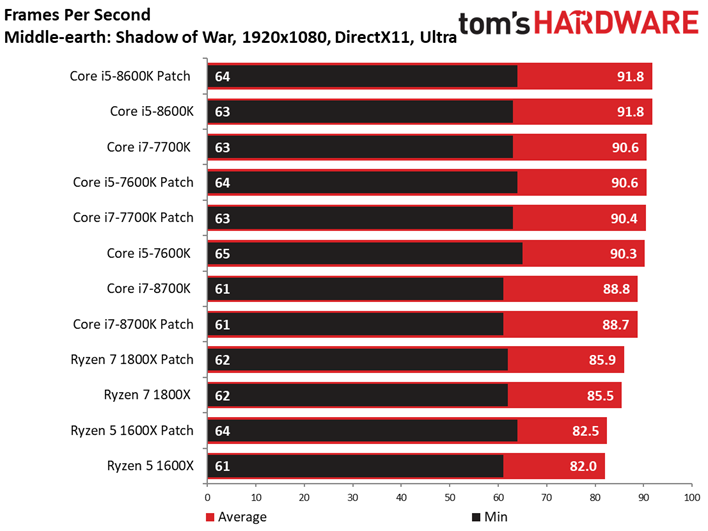
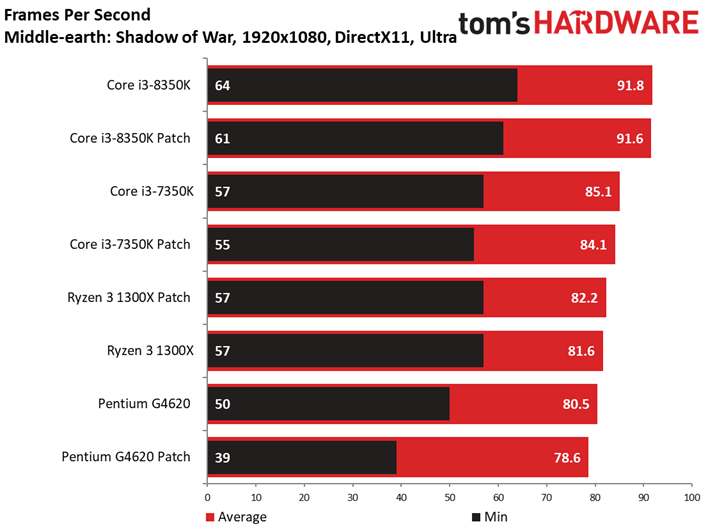
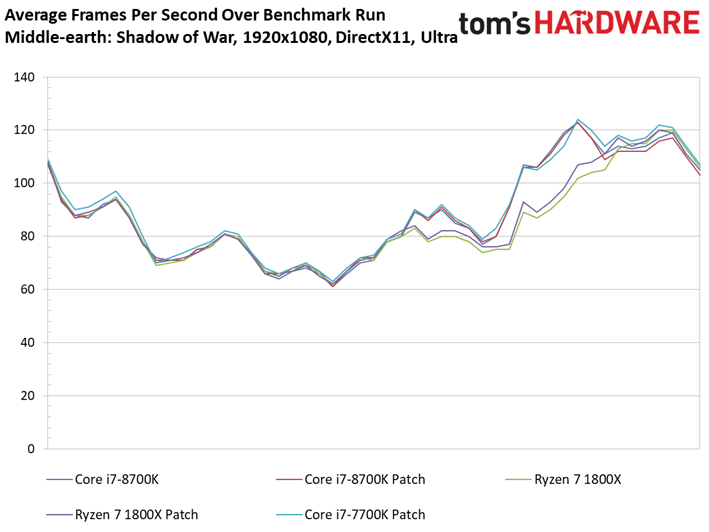
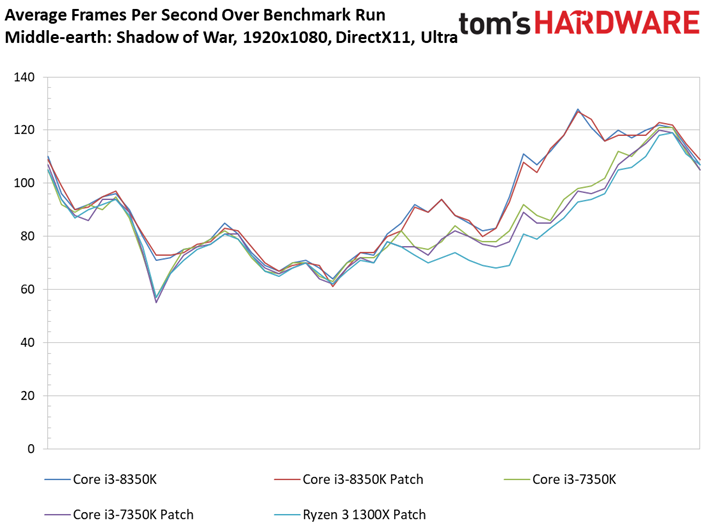
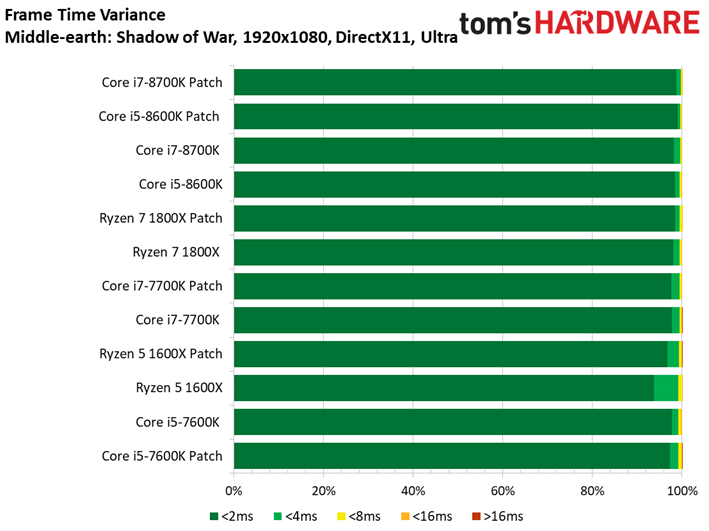
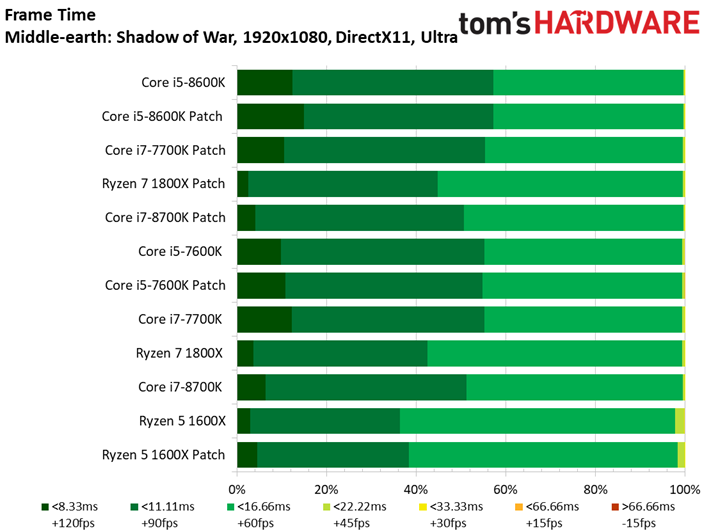
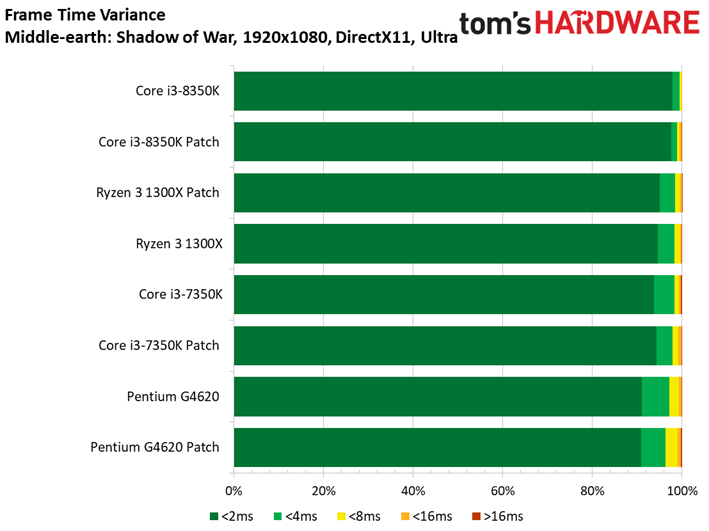
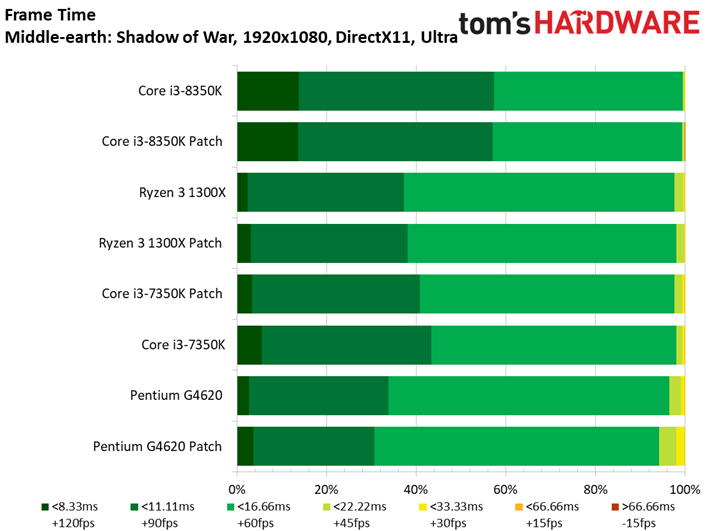
A l’occasion de cet article, nous remplaçons le vieillissant Middle-earth: Shadow of Mordor pour sa suite, Shadow of War. Le benchmark intégré à ce dernier a l’avantage de proposer des résultats d’une constance particulièrement appréciable.
Comme c’est le cas pour de nombreux titres sortis récemment, Shadow of War est moins sensible que son prédécesseur à la fréquence et au débit d’IPC. On ne voit pas grande différence entre Core i5 et Core i7 du fait que le titre de Monolith Productions est essentiellement limité par les ressources graphiques. En revanche, l’entrée de gamme présente des écarts plus marqués. Retenons toutefois qu’il n’y a que 13,2 ips de différence entre le Core i7-8600K et le Pentium G4620.
Project CARS 2 et PUBG
Project CARS 2
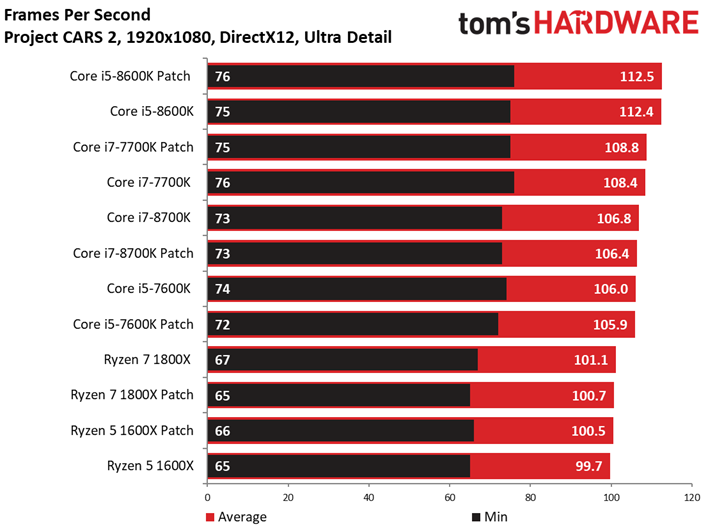
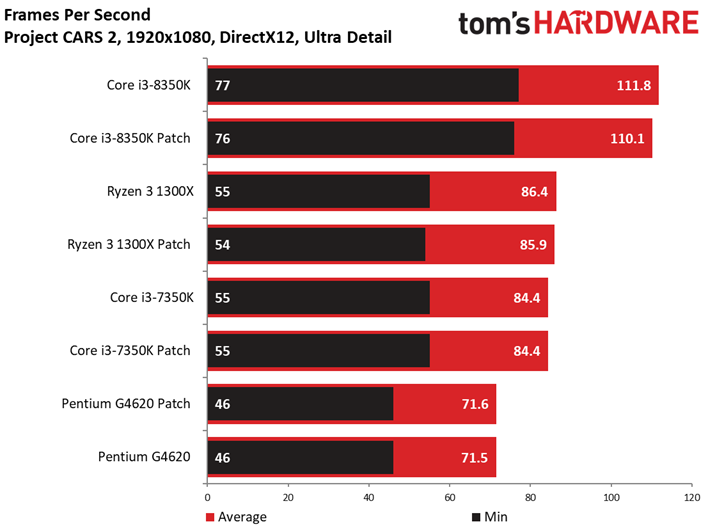
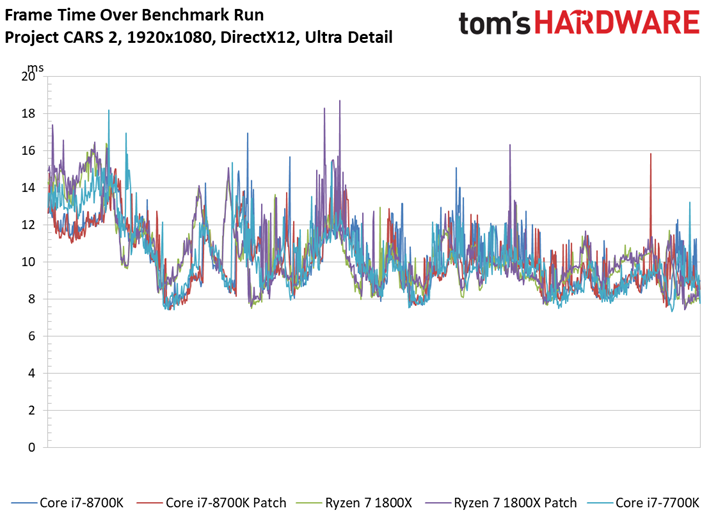
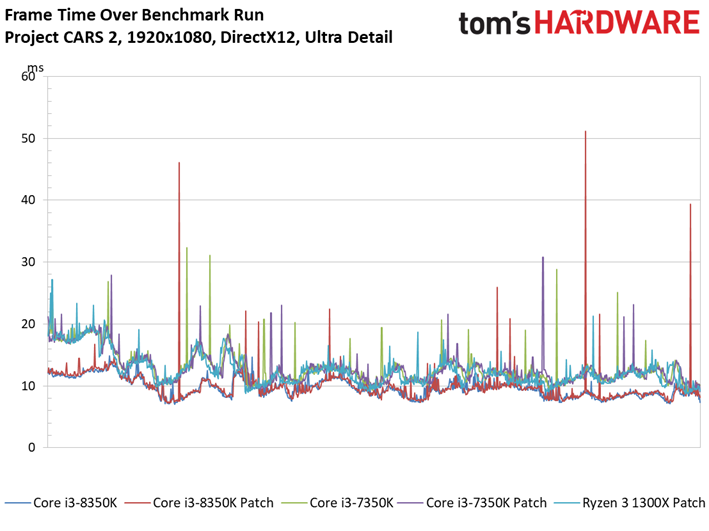
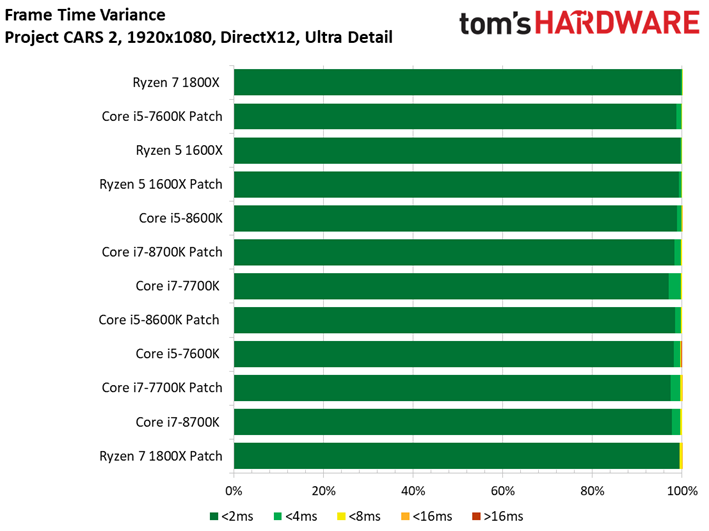
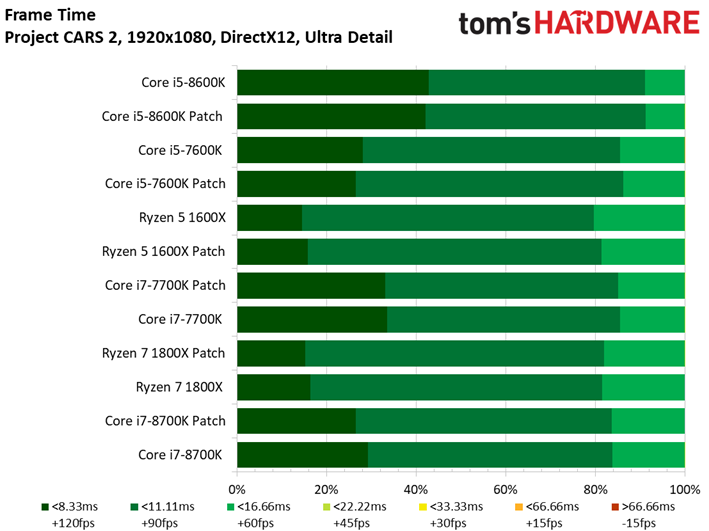
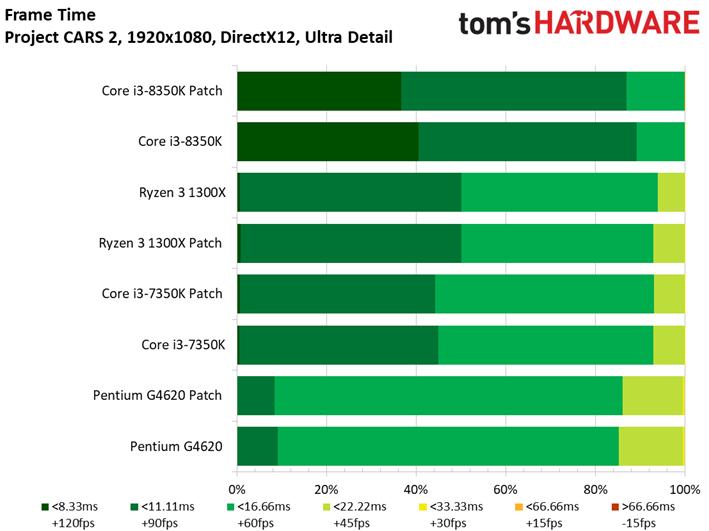
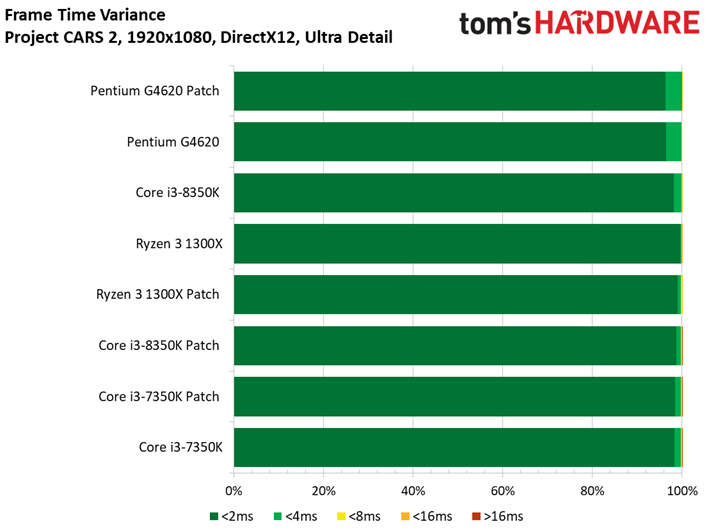
Project CARS laisse aussi sa place à son successeur dans notre suite de tests. Ce jeu permet d’observer un échelonnement des performances légèrement supérieur à Shadow of War, le moins performant des processeurs (Pentium G4620) accusant un déficit de 41 ips par rapport au plus performant. Quoi qu’il en soit, les écarts entre configurations avec et sans patch ne sont toujours pas significatifs : le cas de figure le plus extrême est de 1,7 ips dans le cas du Core i3-8350K, soit une baisse d’environ 2,5%.
PlayerUnknown’s Battlegrounds (PUBG)
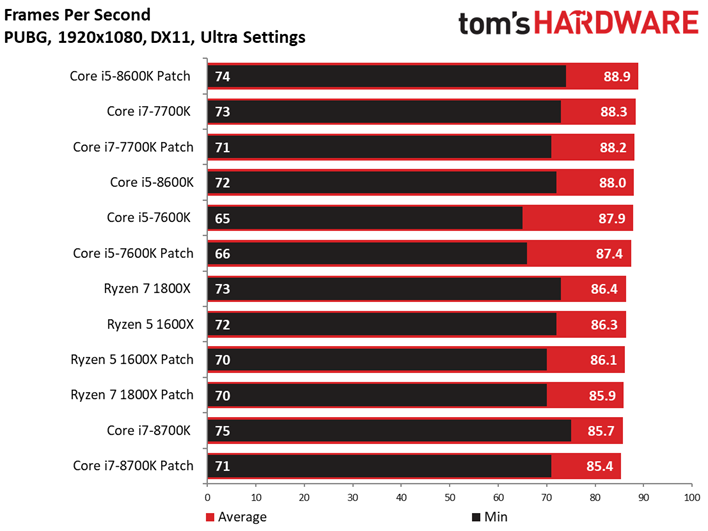
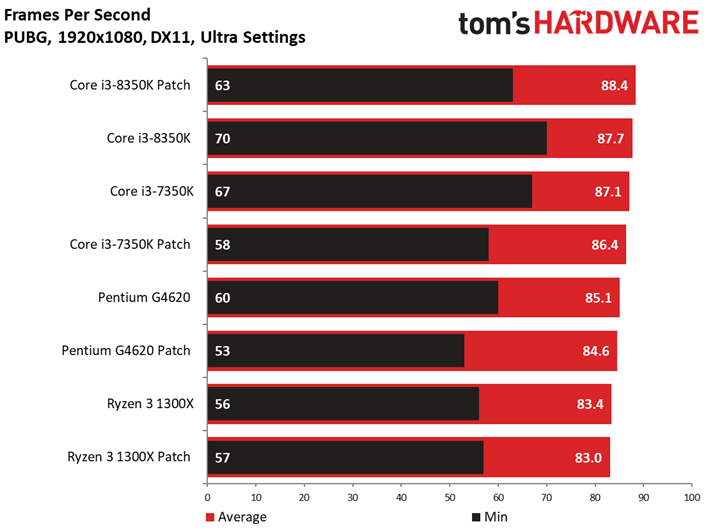
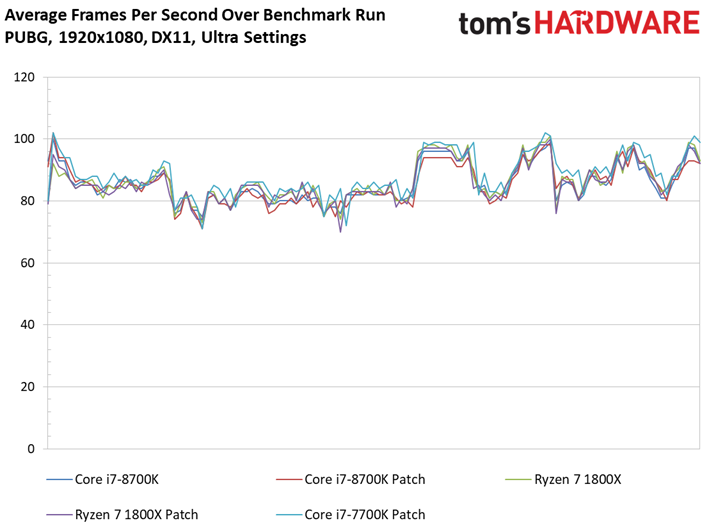
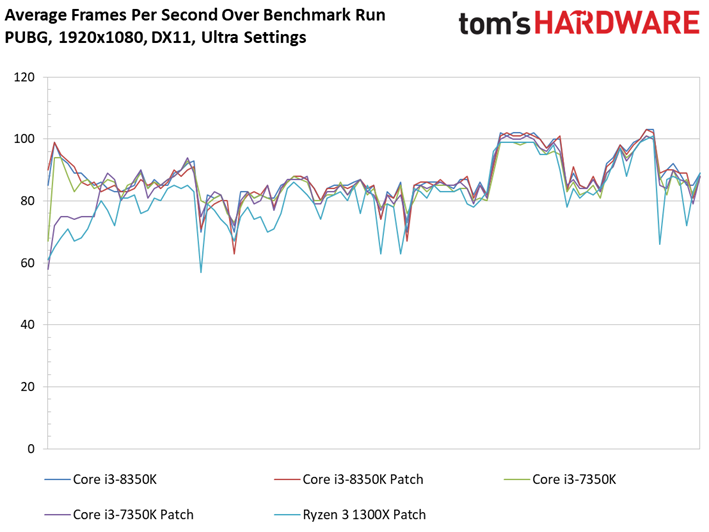
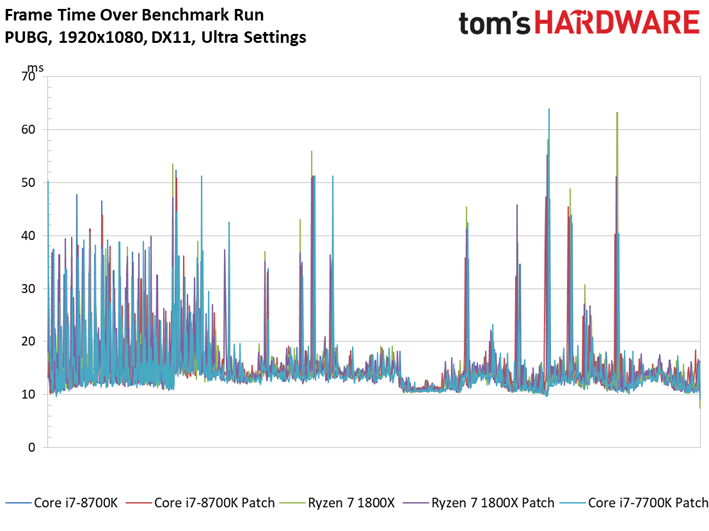
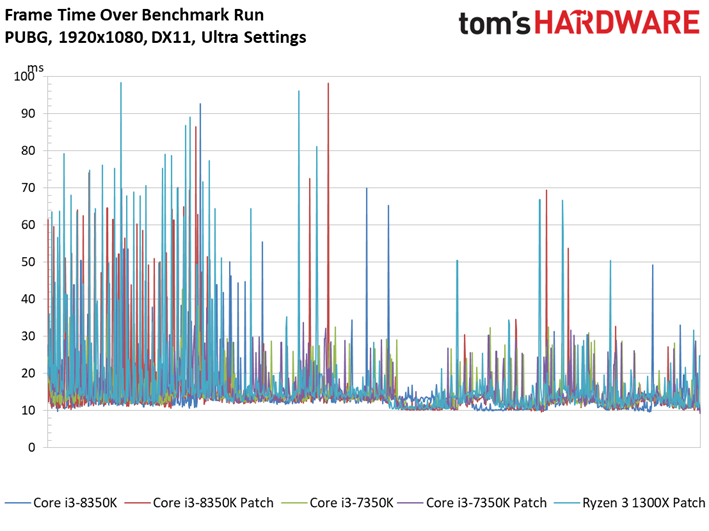
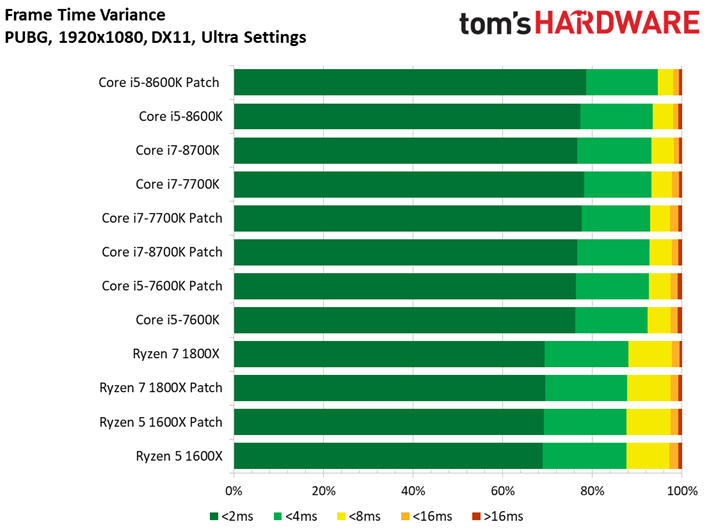
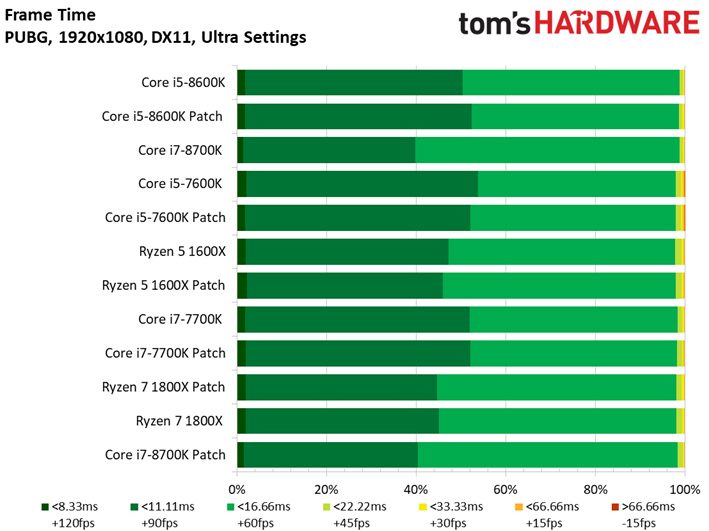
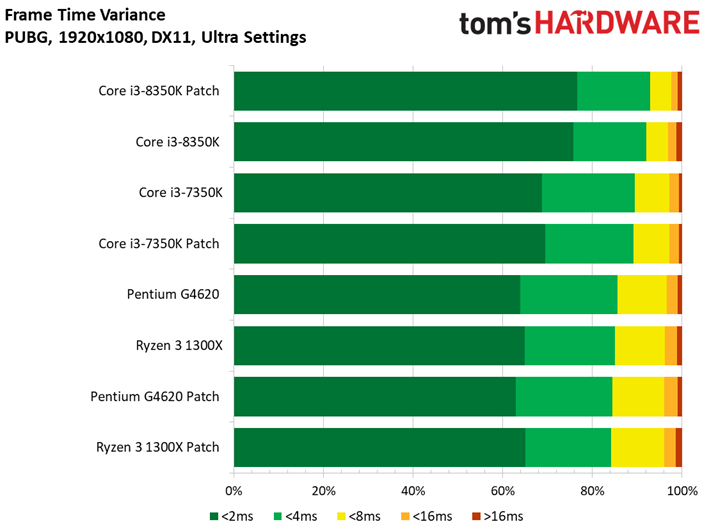
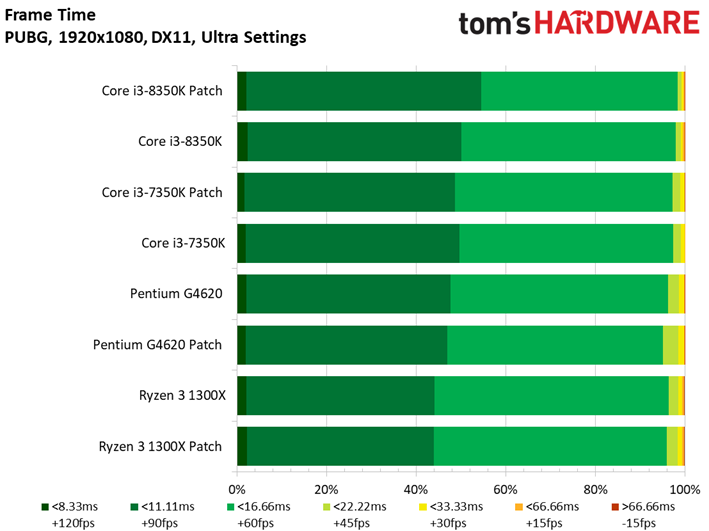
Dernière nouveauté de la suite de tests, PlayerUnknown’s Battlegrounds fait sa première apparition. Bien que l’on fasse appel à une séquence de jeu sauvegardée pour s’assurer du caractère répétable du test, nous avons récemment appris que les enregistrements de PUBG peuvent diminuer les performances de 4 à 8 ips environ par rapport à une session de jeu. Cette tendance est franchement curieuse, les parties sauvegardées ayant plutôt tendance à afficher des performances supérieures à celles de vraies parties multijoueur. Quoi qu’il en soit, nous avons enregistré plusieurs parties avec notre propre utilitaire pour comparer les résultats avec celui du jeu : les courbes de performances dans le temps n’étaient pas identiques, mais les pics et creux étaient similaires. On peut donc en conclure que les enregistrements de PUBG reflètent des tendances de fond en matière de comportement, mais avec des performances moindres que celles d’une partie en direct.
Pour autant, ceci ne veut pas dire que les résultats sont moins intéressants que ceux des précédents titres. Le fait est que le moteur de Bluehole ne voit pas ses performances s’échelonner de manière satisfaisante en fonction du processeur utilisé : il n’y a que 5,9 ips d’écart entre le Pentium G4620 et le Core i5-8600K. On pourrait toujours accentuer cet écart en baissant les réglages graphiques, toutefois nous préférons les pousser au maximum pour le plaisir des yeux plutôt que de concevoir artificiellement un test synthétique. Précisons enfin que nous avons évité de conduire des tests sous PUBG jusqu’ici en raison des mises à jour en rafale ; il n’est donc pas impossible que l’échelonnement des performances s’améliore à l’avenir.
Conclusion : jusqu’ici, tout va bien
 Cette première analyse des répercussions engendrées par les patchs visant Meltdown et Spectre s’est révélée sans histoire. L’ensemble de nos benchmarks, portant uniquement sur les jeux, ne nous a pas donné l’occasion de rapporter grand-chose. Il convient cependant de noter que ce constat tient à la situation des patchs, laquelle évolue régulièrement.
Cette première analyse des répercussions engendrées par les patchs visant Meltdown et Spectre s’est révélée sans histoire. L’ensemble de nos benchmarks, portant uniquement sur les jeux, ne nous a pas donné l’occasion de rapporter grand-chose. Il convient cependant de noter que ce constat tient à la situation des patchs, laquelle évolue régulièrement.
D’autres tests nécessaires
Nous avions ainsi prévu de conduire nos tests avec les patchs niveau OS ainsi que les mises à jour BIOS pour Spectre deuxième variante, ces dernières étant celles qui devraient s’avérer les plus pénalisantes en termes de performances.Manque de chance, Intel et ses partenaires ont retiré le patch microcode au cours de nos tests, tandis qu’AMD n’a pas encore déployé sa propre solution. Nous avons appris que le correctif « mis à jour » d’Intel est en train de suivre un processus de validation rigoureux, sans pour autant avoir eu communication d’une date de sortie ne serait-ce qu’approximative. Il en va de même pour Spectre deuxième variante dans le cas d’AMD. Naturellement, nous ne manquerons pas de revenir sur le sujet dès que ces patchs seront diffusés.
Pour les processeurs les plus récents, il semblerait que les correctifs au niveau du système d’exploitation n’affecteront pas beaucoup les performances en jeu, voire pas du tout. La plupart des jeux sont confinés à l’espace utilisateur et n’adressent pas d’appels réguliers au noyau ; il est donc possible que les conséquences sur les processeurs plus anciens soient également mineures (nous sommes justement en train de nous en assurer).
Un impact sur le stockage ?
En revanche, nous savons que le patch actuel a des conséquences sur les performances en stockage, tout du moins sous l’angle des benchmarks synthétiques. Un périphérique de stockage particulièrement lent aurait bien entendu des conséquences sur les temps de chargement ainsi que la capacité du sous-système de stockage à nourrir le moteur d’un jeu, avec le risque d’avoir des transitions qui rament entre différentes scènes. Nous avons eu un regard vigilant sur nos temps de chargement et scènes préenregistrées : si les processeurs entrée de gamme nécessitaient plus de temps que les modèles haut de gamme pour un résultat moins fluide à la clé, il est délicat de rejeter la faute sur le patch dans la mesure ou les processeurs plus lents sont tout simplement moins performants à la base. Nous n’avons pas non plus relevé de rupture majeure dans la continuité des performances ou la latence inter-images, ce qui nous fait dire que les quelques écarts susceptibles de se manifester se limiteraient vraisemblablement au stockage, tout du moins sur la base des patchs tels que disponibles au moment des tests.
 La plupart des tests de stockage destinés à évaluer les conséquences des correctifs pour Meltdown/Spectre sont effectués avec des files d’attentes particulièrement longues, ou alors sur la base d’opérations exclusivement en lecture ou en écriture qui ne constituent pas le meilleur indicateur possible pour illustrer ce dont un OS ou un moteur de jeu a besoin. En pratique, la plupart des accès se font avec une file d’attente courte et l’on sait que les véritables bouleversements en matière de performances pour les SSD, pour le meilleur ou pour le pire, ne correspondent pas de façon linéaire aux performances applicatives. Nous travaillons sur une série de tests pour un prochain article, lequel permettra de quantifier plus finement les conséquences de cette situation.
La plupart des tests de stockage destinés à évaluer les conséquences des correctifs pour Meltdown/Spectre sont effectués avec des files d’attentes particulièrement longues, ou alors sur la base d’opérations exclusivement en lecture ou en écriture qui ne constituent pas le meilleur indicateur possible pour illustrer ce dont un OS ou un moteur de jeu a besoin. En pratique, la plupart des accès se font avec une file d’attente courte et l’on sait que les véritables bouleversements en matière de performances pour les SSD, pour le meilleur ou pour le pire, ne correspondent pas de façon linéaire aux performances applicatives. Nous travaillons sur une série de tests pour un prochain article, lequel permettra de quantifier plus finement les conséquences de cette situation.
Des patchs pour les patchs
Les correctifs pour Spectre deuxième variante constituent encore un énorme enjeu pour Intel et AMD. Espérons que les deux acteurs pourront proposer des solutions fiables avec un minimum de répercussions sur les performances. Nous avons eu vent du fait que certains programmes peuvent être optimisés de manière à minimiser les latences inhérentes aux correctifs. Intel a par ailleurs déclaré que les patchs actuellement disponibles allaient gagner en maturité de sorte à proposer des implémentations plus efficaces.
Pour l’heure, nous restons donc vulnérables à Spectre deuxième variante, alors que l’on voit malheureusement déjà apparaître des logiciels malicieux s’appuyant sur le code ayant servi à la preuve de concept. Il revient donc à Intel, AMD et tout le reste de l’industrie de corriger efficacement ce qui pourrait être la pire faille de sécurité de notre époque. D’ici là, nous pourrons au moins jouer sans payer les pots cassés.