Introduction
Après de multiples rumeurs pour le moins inquiétantes et un faux départ il y a 2 mois, où le constructeur a annulé à la dernière minute le lancement de son haut de gamme, le R600 est enfin entre nos mains ! Ce n’est pas la première fois qu’une nouvelle génération AMD est en retard, puisqu’il suffit de remonter à la précédente architecture, le X1800, qui avait déjà connu plusieurs aléas avant d’être disponible. Malgré tout dés qu’un GPU qu’on annonce comme révolutionnaire joue les arlésiennes, le spectre de la GeForce FX resurgit forcément.


La GeForce 8800 GTX mérite-t-elle sa place dans cette courte liste ? Réponse dans quelques pages, le temps de revenir en détail sur l’architecture de la nouvelle puce AMD, d’isoler ses performances synthétiques, les nouveautés de son moteur vidéo, de l’antialiasing, des performances sous les meilleures jeux actuels, sous DirectX 10, sans oublier de comparer la qualité d’image pour chaque jeu !
Xenos, le précurseur
Avant de nous attaquer au R600 à proprement parler, permettez nous de faire un petit détour pour vous présenter le Xenos. Les fans de consoles le savent peut être, pour les autres sachez que le Xenos est le GPU conçu par ATI que l’on retrouve au sein de la Xbox 360. Pourquoi parler de consoles alors que l’on s’intéresse à un GPU PC ? Et bien c’est simple : le Xenos a eu une influence certaine sur l’architecture du R600 et pour bien le comprendre rien de tel qu’une petite présentation de ce GPU atypique. Promis ce surplus de lecture ne sera pas inutile !
Le Xenos a été l’occasion pour ATI d’expérimenter tout un tas de nouvelles idées et en premier lieu une sur laquelle ils travaillaient depuis un moment : l’unification des unités de shaders. Nous en avons déjà parlé lors de notre test du G80, premier GPU PC à utiliser des shaders unifiés, mais il ne faut pas oublier qu’ATI a été le premier à proposer un GPU de ce type tout court.
Pour rappel l’intérêt d’utiliser des unités arithmétiques unifiées pour effectuer les calculs est de permettre de faire de la répartition de charge. Ainsi, contrairement aux GPU existants avant lui, le Xenos ne dispose plus d’un certain nombre d’unités dédiées aux calculs sur les vertex et d’autres dédiées aux pixels, il dispose juste de 48 ALU qui sont attribuées dynamiquement aux différentes tâches.
En pratique, comme on le voit sur ce diagramme, ces 48 ALU sont organisées en 3 shader pipes de 16 ALU. Ainsi en premier lieu le GPU commence par regrouper des primitives (vertex ou pixel) partageant le même état de rendu dans des vecteurs de 64 éléments (chaque élément lui-même étant composé de 4 valeurs flottantes 32 bits : x,y,z,w ou r,g,b, a). Ensuite ces vecteurs de 64 éléments sont envoyés au sequencer où ils attendent qu’un shader pipe soit disponible. Lorsque c’est le cas le vecteur est envoyé dans cette unité pour être exécuté. Ces shader pipes sont en fait des grosses unités SIMD (Single Instruction Multiple Data) qui effectuent les calculs sur les 64 éléments simultanément en 4 cycles.
La première instruction du shader est appliquée sur les 16 premiers éléments, puis sur les 16 suivants et ainsi de suite jusqu’à ce que les 64 élément aient été traités. Ensuite la deuxième instruction est appliquée, tout ceci étant évidemment pipeliné. Cette technique permet de masquer complètement la latence de l’ALU, ainsi aux yeux du programmeur tout se passe comme si chaque instruction était exécutée en un cycle.
Le précurseur (ALU, caches et texture arrays)
Intéressons nous maintenant aux ALU plus précisément :
Comme on le voit sur ce schéma, les ALU du Xenos sont vectorielles et co-issue : elles peuvent appliquer simultanément une instruction sur un vecteur de 4 éléments et sur un scalaire. En fait elles sont assez proches des ALU que l’on retrouvait dans les vertex shaders sur les précédentes architectures : la portion scalaire ne pouvant pas appliquer de MAD (instruction de multiplication addition fusionnée), elle n’est utilisée que par les fonctions plus complexes comme l’inverse, la racine carrée, sinus, cosinus etc. Une autre petite limitation est que si une instruction utilisant trois opérandes (un MAD) est appliquée dans l’unité vectorielle alors l’unité scalaire ne peut être utilisée que sur un élément du troisième opérande.
Exemple :
Autre particularité intéressante de cette architecture, on retrouve 32 unités de fetch de données : 16 qui peuvent filtrer les données (en clair des unités de texture “classiques”) et 16 qui ne filtrent pas les données (des unités de vertex fetch). Là où cela devient amusant c’est que désormais les shaders qu’ils soient vertex ou pixel peuvent accéder à ces deux types de fetch. Un vertex shader peut donc sampler une texture avec le même niveau de fonctionnalités qu’un pixel shader, et ce dernier a accès à l’équivalent de 32 unités au maximum, dans le cas où le filtrage n’est pas nécessaire.
Evidemment les patterns d’accès aux données étant très différents entre une texture (qui est souvent bidimensionnelle) et un tableau de sommets, les mémoires caches reflètent ces différences : le cache de textures de 32 Ko est optimisé pour l’accès à des ressources 2D ou 3D et sert principalement à accélérer le filtrage de textures. Le cache de vertex ne fait pour sa part que 8 Ko, est optimisé pour accéder à des données 1D et ne sert qu’à économiser la bande passante.
Au niveau de l’accès aux textures, le Xenos a introduit une fonctionnalité qu’on retrouve aujourd’hui étendue dans Direct3D 10 : les textures arrays. Ainsi ce GPU supporte des tableaux de 64 textures, chacune pouvant contenir les niveaux mipmaps associés, et stockés de façon contiguë en mémoire. Contrairement à une texture 2D il n’y a pas de mipmap dans la 3ème dimension on a donc accès à 64 textures 2D indépendantes les unes des autres (elles partagent juste les mêmes dimensions) et non pas à une texture volumique dont la 3ème dimension est 64.
Le précurseur (fonctionnalités GPGPU, tesselation)
Autre fonctionnalité révolutionnaire pour un GPU : le MEMEXPORT qui permet au Xenos d’écrire dans la mémoire à des positons arbitraires (le fameux scatter write qui plaît tant aux développeurs d’applications GPGPU). Evidemment, il y a des contraintes qui peuvent rendre cette technique délicate à utiliser, en particulier l’absence de gestion automatique de la cohérence entre les lectures et les écritures. C’est donc au programmeur de s’assurer qu’une écriture a bien été terminée avant d’effectuer une lecture en plaçant des commandes de synchronisation dans le command buffer. Malgré cette difficulté les possibilités du MEMEXPORT sont très intéressantes, par exemple dans le cas de skinning complexe (déformation d’un maillage de points en utilisant un squelette). Cette technique permet de réaliser des animations à partir d’un seul maillage au lieu de stocker plusieurs maillages représentants des positions intermédiaires entre lesquelles il faudra interpoler. Il peut alors être intéressant de stocker le résultat du calcul dans un buffer et ensuite dans les autres passes de réutiliser la version skinnée plutôt que de devoir refaire les calculs.
Terminons ce petit tour d’horizon du Xenos en vous parlant de la dernière nouveauté introduite par ce processeur : une unité de tesselation. Selon ATI c’est Microsoft lui-même qui a insisté pour avoir une unité de ce type dans son GPU. A quoi sert une unité de tesselation ? Et bien à générer de nouveaux sommets. Mais ce n’est pas nouveau : on a connu ça il y a bien longtemps avec le Truform me répondrez vous… Oui mais là où le Truform n’était capable d’effectuer la tesselation que selon un algorithme bien précis (transformation du mesh en N-patches puis subdivision de ces N-patches) cette fois l’unité de tesselation du Xenos est extrêmement flexible et permet au programmeur de choisir l’algorithme qu’il préfère pour réaliser sa subdivision.

D’ailleurs contrairement au Truform qui a rapidement été abandonné par ATI faute d’intérêt des développeurs de jeux, l’unité de tesselation du Xenos a déjà été utilisé et semble ravir les développeurs, notamment ceux de RARE qui s’en sont servis pour leur moteur de rendu de terrain dans Viva Piñata (Xbox 360 donc).

Le prédécesseur, DX10, R600
Le prédécesseur
Cette fois pas question de vous refaire la description de l’architecture X1000 d’ATI, si vous êtes un fidèle lecteur de Presence-PC vous avez déjà lu nos précédents articles (sur l’architecture X1800 et X1900). Toutefois si vous souhaitez vous rafraîchir la mémoire sans vous replonger dans nos articles voici les principaux éléments qu’il faut retenir de l’architecture précédente d’ATI :
- Une architecture fortement threadée et découplée (ultra-threaded architecture et unités de textures séparées des ALU)
- Une gestion des accès mémoires revue pour plus d’efficacité et d’évolutivité (topologie en anneau notamment)
- Un rapport ALU/TEX inversé en favorisant les ALU par rapport aux instructions de texture (X1600 et X1900)
Direct3D 10
Là encore pas question de rentrer dans les détails de Direct3D 10 auquel nous avons réservé un article complet il y a quelques mois mais on peut résumer les apports de cette API en quelques points :
- Amélioration des performances en diminuant le surcoût de l’API
- Unification des fonctionnalités et des ressources entre les différents types de shaders
- Introduction des geometry shader pour se libérer de la contrainte “1 sommet entrant – 1 sommet sortant”
- Introduction du StreamOutput afin de pouvoir écrire dans la mémoire plus tôt dans le pipeline
R600
Et nous pouvons enfin nous intéresser au R600, mais rassurez-vous tout ce que nous venons de voir n’est pas inutile car le R600 est en quelque sorte la fusion du Xenos et du X1900 le tout étendu à DirectX 10 et avec bien plus de ressources de calculs.
| HD 2900 XT (R600) | |
|---|---|
| Fréquence GPU | 742 MHz |
| Fréquence RAM | 825 MHz |
| ALU | 320 |
| Unités de texture | 16 filtrées / 16 non filtrées |
| Color ROP | 16 |
| Z ROP | 32 |
| Contrôleur mémoire | 512 bits (8 canaux 64 bits) |
| Type de RAM | GDDR3 |
La première chose qui frappe lorsque l’on regarde le tableau ci-dessus c’est le nombre d’ALU : 320, mais comme avec le G80 il faut se montrer prudent : on ne parle plus ici d’ALU vectorielles mais d’ALU scalaires. En pratique cela correspondrait donc à 80 pipelines 4D vectoriels mais la réalité est plus complexe, nous y reviendrons très bientôt.
Autre élément intéressant : nous avons ici le premier GPU à disposer d’un bus 512 bits et ce 5 ans après l’introduction du bus 256 bits par Matrox ! Avec de la GDDR3 à 825MHz on obtient donc la bande passante assez délirante de près de 106 Go/s. En revanche, contrairement à son concurrent, AMD n’en a pas profité pour augmenter le nombre de ROP qui reste désespérément figé à 16 depuis le R420 en 2004. Idem pour le nombre d’unités de textures qui est lui aussi inchangé. AMD justifie pour sa part l’augmentation de bande passante comme étant nécessaire pour offrir enfin du HDR avec un impact le plus bas possible sur les performances. Le retour du “think less about more pixels and more about better pixels” en quelque sorte, David Kirk (Chief Scientist de nVidia) appréciera sûrement…
Au final ce GPU dont la conception aura durée près de 4 ans et aura impliquée jusqu’à 300 personnes comprend 700 millions de transistors selon AMD, ce qui lui permet de coiffer sur le poteau NVIDIA et son G80 avec ses 681 millions.
Vue d’ensemble, communications CPU-GPU
Une vue de haut niveau de l’architecture du R600 vous le confirmera : on retrouve bien les caractéristiques de l’architecture R5x0 et de celle du Xenos combinées. Ainsi on dispose d’un ensemble d’ALU alimentées par une unité qui se charge de gérer les quelques centaines de threads en cours d’exécution à tout moment.
Tout en haut du diagramme on trouve donc le Command Processor. Pour comprendre son rôle il faut savoir comment communiquent le CPU et le GPU. Tout se passe très simplement : le CPU écrit des commandes dans un tampon en mémoire centrale, le GPU récupère ces commandes et les exécute.
Il s’agit en fait d’un pattern très courant de programmation parallèle appelé “producteur-consommateur” qui permet un niveau élevé de parallélisme : le CPU et le GPU travaillent indépendamment l’un de l’autre. A l’inverse si le CPU envoyait une commande au GPU à la fois, chacune des deux unités serait inutilisée une partie du temps : le temps que le CPU envoie la commande le GPU n’a rien à faire, lorsque le GPU traite la commande le CPU n’a rien à faire.
Avec ce modèle les seuls cas où le parallélisme peut être brisé sont au nombre de trois :
- Lorsque le tampon est plein, le CPU ne peut plus rien écrire, et perd des cycles à ne rien faire
- Lorsque le tampon est vide, le GPU n’a plus rien à exécuter
- Lorsque le programmeur insère dans le tampon de commandes une commande qui force une synchronisation explicite. C’est par exemple le cas en OpenGL de la commande glFinish qui garantit que toutes les commandes en attente seront exécutées avant que la fonction ne retourne son résultat. Ce genre de commandes est de ce fait très largement déconseillé dans les situations où les performances sont critiques.
Certains cas de synchronisation sont plus subtils, ainsi lorsque le CPU décide de verrouiller un vertex buffer pour modifier les données qu’il contient, si le GPU n’a pas encore traité la commande de rendu précédente de ce vertex buffer il faut attendre que ce soit le cas. En effet il faut garantir au programmeur l’illusion d’une exécution totalement séquentielle du programme comme si chaque commande était exécutée instantanément. Le programmeur s’attend donc à voir d’abord s’afficher son premier modèle, ensuite à le modifier et à voir s’afficher le nouveau modèle. Sans synchronisation une modification du vertex buffer affectera aussi la première commande de rendu et ce n’est pas ce qu’il souhaitait.
Command Processor, setup engine, arbitrer et sequencer
Le Command Processor du R600 a pour sa part été totalement remanié. Il s’agit non pas d’une unité fixe mais d’un processeur programmable par le biais d’un microcode. On a beaucoup parlé avec DirectX 10 de la réduction du surcoût CPU de l’API ; AMD pour sa part a décidé de s’attaquer au surcoût CPU de son driver, ainsi ce tout nouveau Command Processor se charge du travail de validation des commandes libérant ainsi des cycles CPU pour d’autres tâches. La validation des commandes garantit que celles-ci sont dans un format correct pour être exécutées par le GPU. D’après AMD cette technique permet d’obtenir jusqu’à 30 % de réduction du surcoût CPU du driver et bien évidemment cela s’applique indépendamment à DirectX9, DirectX 10 ou OpenGL. Attention à ne pas mal interpréter ce chiffre : le surcoût CPU du driver est en général d’à peine 5%, ne vous attendez pas à voir 30% de réduction sur l’utilisation globale du CPU ! Malgré tout c’est un plus qui reste appréciable.
Ensuite on trouve donc le setup engine mais celui-ci est bien différent d’un setup engine traditionnel dont le rôle est habituellement de réaliser ce que l’on appelle la scan conversion. Il s’agit tout simplement du procédé qui consiste à prendre les trois sommets constituants un triangle et à déterminer les pixels (ou plus exactement les quads, vu que comme vous le savez les GPU modernes travaillent sur ces petits carrés de 2×2 pixels) que ce triangle recouvre.
Ici le setup engine a un rôle bien plus générique. Pour rappel on peut traduire setup en français par “organisation”, le setup engine du R600 organise donc les données avant de les passer au dispatch processor mais pas seulement les données de pixels, également les données géométriques et de sommets ! Il prépare donc les threads de vertices, géométries, ou pixels avant de les envoyer au dispatch processor. Comme sur le Xenos les threads sont en fait des vecteurs de 64 éléments, chacun d’entre eux étant composé de 4 flottants simple précision. Lorsqu’un vecteur est plein il est envoyé dans une file où il attendra d’être exécuté.
On trouve ensuite des unités appelées arbitrer et sequencer. Le rôle des arbitrer est de déterminer quel thread exécuter ensuite en fonction de divers paramètres qui définissent sa priorité. Mais pourquoi deux arbitrer par array SIMD ? La réponse est un peu technique : comme nous l’avons vu sur notre vue d’ensemble du Xenos, la première instruction d’un thread est appliquée sur 16 éléments, puis sur les 16 suivants jusqu’à avoir traité les 64. Ensuite la deuxième instruction est exécutée. Cette technique permettant de masquer 4 cycles de latence d’une ALU. En fait l’ALU a 8 cycles de latence donc pour complètement la masquer il faut entrelacer l’exécution de deux threads : un thread étant exécuté durant les cycles pairs, l’autre les cycles impairs.
Le sequencer pour sa part réordonne l’ordre des opérations afin d’obtenir une utilisation maximale des ALU.
Les ALU dans le détail, l’unité de tesselation
Comme vous l’avez vu sur le schéma de haut niveau les ALU reprennent peu ou prou la même organisation que sur le Xenos. Ainsi sur ce dernier on disposait de 3 arrays SIMD de 16 unités vectorielles 5D ; sur le R600 on trouve 4 arrays SIMD de 80 unités scalaires. Dans les deux cas une array SIMD travaille donc sur 80 valeurs flottantes simple précision simultanément. Mais si l’on y regarde de plus près ces ALU sont différentes de celles du Xenos.
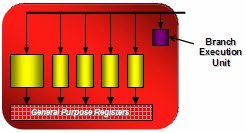
Tout d’abord ces unités sont scalaires, à l’image de celles du G80, de plus il est désormais possible d’exécuter 5 MAD par cycle alors que comme nous l’avons vu le Xenos ne pouvait appliquer un MAD que sur 4 éléments. Enfin on retrouve l’unité de branchement qui avait fait son apparition avec le X1800 et qui garantissait que la surcharge induite par un branchement était la plus faible possible.
Les autres modifications concernent le passage à DirectX 10 et notamment le support des opérations entières et des opérations logiques bit à bit. Sur ces 5 unités, 4 sont capables d’exécuter des additions entières ou logiques, mais seule une est capable d’exécuter également des multiplications entières. C’est également cette unité qui se charge des fonctions transcendantales (sinus, cosinus, log, exp, …).
Avec 320 unités capables d’effectuer une FMAD chacune, le R600 obtient donc une performance de crête en virgule flottante de 474.88 GFlops (0.742 GHz x 320 ALU x 2 ) dans la même situation le G80 plafonne à 345.6 GFlops (1.35 GHz x 128 ALU x 2). Evidemment on parle ici d’un shader constitué uniquement de multiplication-addition flottante, c’est un cas théorique qui n’a que peu d’intérêt, mais il s’agit tout de même d’une puissance de calcul programmable alors qu’il y a quelques années les chiffres donnés par les fabricants de GPU étaient plus que fantaisistes et incluaient tout et n’importe quoi. Il est donc assez impressionnant de voir une telle puissance développée par une carte grand public haut de gamme alors qu’il y a dix ans une performance comme celle-ci l’aurait placée directement dans le top 3 des supercalculateurs les plus puissants du monde.
Comme il y a 5 unités indépendantes il n’est plus question ici de co-issue vecteur/scalaire : les unités d’exécution sont des unités VLIW (Very Long Instruction Word) qui reçoivent des bundles de 512 bits contenant 5 instructions arithmétiques et 1 instruction de branchement.
L’unité de tesselation
Surprise alors que l’unité de tesselation a disparu du pipeline de DirectX 10, les ingénieurs d’AMD ont malgré tout choisi de l’intégrer à leur GPU. Il faut dire que le travail requis était des plus limité car ils ont repris l’unité apparue avec le Xenos. On le sait, l’amplification massive de géométrie dans un geometry shader est loin d’être recommandée pour les performances, aussi cette unité de tesselation peut s’avérer très utile. E revanche son absence sur les GPU NVIDIA, et surtout son absence au sein de DirectX 10 devrait fortement limiter son utilisation dans nos futurs jeux.
Performances en vertex shading
Voyons dans un premier temps comment se comportent nos nouvelle architecture face à l’ancienne d’ATI sur un test reposant seulement sur la puissance en vertex shading.
Evidemment, le passage de 8 vertex shaders à 320 stream processors se fait sentir, même si encore une fois ces deux unités ne sont pas comparables. Reste que sur ce test synthétique, la HD 2900 XT parvient à développer une puissance 4 à 7 fois supérieure que la précédente génération, ce qui est un record. Mieux : cette puissance est également supérieure à celle de 8800 GTX dans tous les cas. C’est ici le surnombre d’unités qui parle, même si on est loin de la différence que l’on pourrait espérer vu un nombre d’unités unifiées de 128 d’un côté et de 320 de l’autre, comme le marketing d’AMD se plaît à le marteler. Il faut dire que quand on prend la fréquence très élevée des streaming processors du G80 en compte, la différence de puissance tombe à 37 % en faveur de la carte AMD ! Ce qui est correspond effectivement à l’avance maximum qu’elle détient sur ce test, bien que dans la plupart des situations on reste aux alentours de 15 %. En effet, nous pensons que les deux architectures unifiées sont peut-être limitées par leur setup engine ici.
Performances en pixel shading
Commençons l’analyse de la puissance en pixel shading avec Fillrate Tester et des Pixel Shaders 2.0.
Bien que supérieure à la 8800 GTX sur un shader long (dans une mesure difficile à estimer vu qu’en fait la 2900 XT est ici encore limitée par ses ROP), un shader complexe d’éclairage par pixel place la carte d’AMD derrière celle de nVidia (-12 %) ! Ce, malgré le gain de 72 % par rapport à la précédente architecture.
Voyons maintenant ce qu’il en est avec Shadermark et ses 16 premiers Shaders 3.0.
Confirmation du dernier résultat, puisque sur aucun de ces shaders, la HD 2900 XT ne parvient à prendre l’avantage sur la 8800 GTX, qui la surpasse souvent d’environ 20 % ! L’évolution par rapport à la X1950 XTX est de même assez limitée.
Terminons avec les 9 derniers shaders, les plus complexes (ils mesurent l’impact de l’alpha blending, de changements répétitifs de shaders, d’un contrôle de flux dynamique, du filtrage en virgule flottante, et de plusieurs render targets).
Le résultat est ici similaire, à une exception notable, les shaders 21, 22 et 23, ceux mesurant l’impact du filtrage en virgule flottante avec un shader HDR. Ici, la 8800 GTX se montre insensible à la qualité du shader ainsi qu’à la présence ou non du filtrage, alors que la HD 2900 XT semble avoir plus de mal en l’absence de filtrage en virgule flottante. Mais dans les trois cas, elle reste devant la 8800 GTX. A noter que les 3 cartes se montrent significativement plus rapides (environ 40 %) suite à l’utilisation d’un contrôle de flux (shaders 19 et 20, dual layer 8×8 PCF Shadow Mapping).
Virtualisation des ressources
Avec DirectX 10 Microsoft a augmenté significativement les limites autrefois imposées aux différents shaders. Ainsi le nombre de registres temporaires passe de 32 à 4096, le nombre de constantes de 256 à 65 536 (16 x 4096) et le nombre de slots d’exécution passe de 512 à 65 535. Plus question de stocker tout cela dans des registres car il faut évidemment pouvoir en garder une copie pour chaque thread, par conséquent AMD a décidé d’utiliser une approche plus similaire à celle que l’on trouve dans les CPU.
Ainsi le GPU récupère ses instructions directement depuis un shader instruction cache, le code du shader n’est donc plus entièrement stocké sur la puce. Grâce à cette mémoire cache on peut s’affranchir de toute limite sur le nombre d’instructions, les instructions du shader sont stockées en VRAM et ramenées dans la mémoire cache uniquement lorsqu’elles sont nécessaires pour l’exécution du shader. De la même façon le nombre de constantes est là aussi virtuellement illimité vu qu’AMD a également ajouté un shader constant cache.
Puisque l’on parle de mémoire cache signalons aussi la présence de ce qu’AMD appelle le memory read/write cache qui est accessible aux 320 stream processors. Le rôle de cette mémoire est multiple : elle permet tout d’abord de virtualiser le nombre de registres temporaires. En effet, même avec DirectX 9 qui ne demandait que 32 registres temporaires, les GPUs n’étaient pas capables d’en offrir un tel nombre pour chaque thread. Lorsqu’un shader nécessitait plus d’un certain nombre de registres temporaires, il fallait réduire le nombre de threads en cours de traitement. Désormais dans une situation comme celle-ci il sera possible de stocker les données des registres supplémentaires dans cette mémoire cache.
Cette mémoire cache est aussi utilisée notamment pour le geometry shader. Comme nous vous l’avions indiqué dans notre article sur DirectX 10, un geometry shader peut générer jusqu’à 1024 valeurs flottantes 32 bits et doit garantir l’ordre d’exécution des primitives. Comme là encore il n’est pas possible de conserver tout ça dans des registres, cette mémoire cache est utilisée lorsqu’un geometry shader génère plus de données que le GPU ne peut en conserver dans ses registres. Enfin cette mémoire cache peut aussi être utilisée pour la communication entre les différents threads.
Les unités de texture
Même si leur nombre reste figé à 16, AMD a quand même apporté quelques modifications à ses unités de texture. Tout d’abord comme sur le Xenos on se retrouve en fait avec 32 unités de texture au total : 16 filtrées, et 16 non filtrées. Ces unités sont aussi plus puissantes que celles du Xenos ou de l’architecture X1000 car elles peuvent filtrer les textures FP16 en un cycle et les textures FP32 en deux cycles.
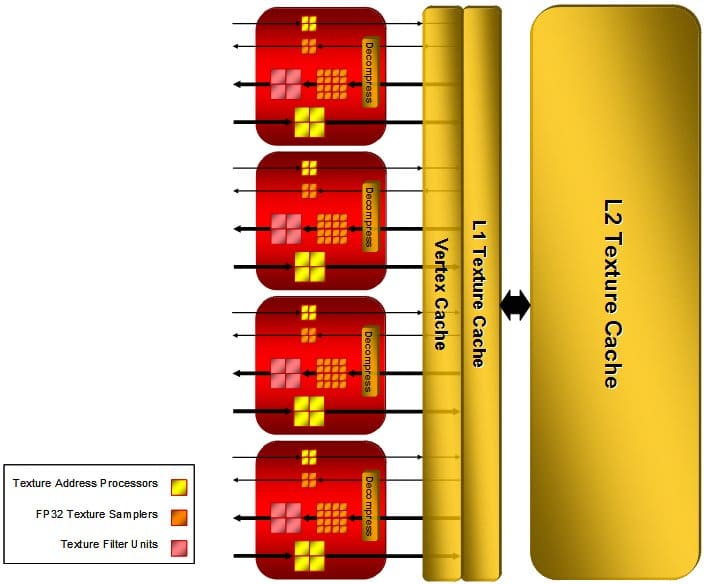
AMD a également totalement remaniée la gestion de sa mémoire cache dédiée aux textures, désormais le R600 emploie une hiérarchie à deux niveaux : on trouve donc une texture cache L1 de 32 Ko, soit la même taille que la texture cache totale du Xenos, et en plus une mémoire cache L2 de 256 Ko. Le cache de vertex pour sa part reste à un seul niveau mais sa taille a été multipliée par 8, il fait désormais 32 Ko.
Notons pour être complet que les unités de texture gèrent les textures DST en conjonction avec le PCF (pour plus d’informations, cf cet article.
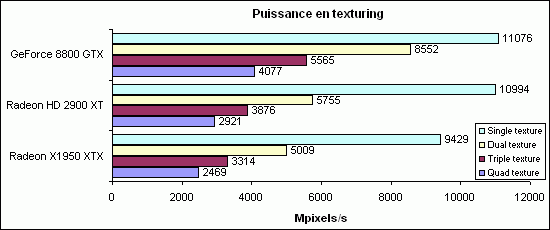
Avec ses 16 unités de textures ici, la HD 2900 XT ne peut pas lutter face aux 32 unités de la 8800 GTX, malgré la différence de fréquence (742 MHz contre 575 MHz). En single-texturing, on reste au niveau du fillrate pure (voir page suivante), mais ensuite, la 8800 GTX demeure 50 % à 40 % plus performance sur ce point que la HD 2900 XT, sur ce test assez simpliste il est vrai. Reste que même comparé à la précédente génération ATI, l’évolution reste inférieure à 20 % ce qui est décevant malgré tout ce que AMD peut affirmer sur l’importance des shaders sur les textures dans les jeux actuels et futurs.
Les ROP, l’interface mémoire
Au niveau des ROP AMD a également profité du passage à DirectX 10 pour apporter quelques modifications. En premier lieu comme sur les cartes NVIDIA pre-G80 et comme sur le Xenos, ces ROP sont capables de doubler leur fillrate dans les passes Z. C’est une bonne chose mais il faut avouer que cela fait un peu pâle figure à côté du G80 dont les 24 ROP sont capables de multiplier par 8 leur fillrate dans ces conditions !
AMD a également rendu ces ROP plus performants lors des opérations de render-to-texture. Ces opérations sont extrêmement utiles lors des effets de post-traitement appliqués à une image, le principe consiste à effectuer le rendu dans une texture au lieu de le faire dans le frame buffer et ensuite d’appliquer les opérations de post-traitement dans une passe suivante dans les unités de shader. Evidemment cela nécessite une synchronisation entre les ROP et les unités de texture pour s’assurer de la cohérence des données : les ROP doivent terminer leur rendu avant que les unités de texture n’essaient d’y accéder. Jusqu’ici tout ceci était géré au niveau du driver mais désormais cette gestion de la cohérence est prise en charge de façon matérielle.
Les ROP sont désormais capables de gérer 4 samples par cycle comme sur le Xenos ou le G80. Ce n’est pas tout : il y a aussi du nouveau du côté de l’antialiasing, mais nous le verrons plus loin dans la partie qui lui est dédié. Pour l’heure, vérifions déjà à l’aide d’un test de fillrate le comportement des ROP.
Concentrons nous d’abord sur le fillrate pur : avec ses 24 ROP et ses 575 MHz de fréquence, la GeForce 8800 GTX est proche du résultat théorique (13,8 GPixels). La HD 2900 XT dispose comme nous l’avons vu d’une fréquence supérieure (elle ne dispose en effet que d’une fréquence globale pour tout le GPU, contrairement au G80), mais est malheureusement limitée à 16 ROP. Résultat ? Son fillrate est un peu moins bon que celui de la 8800 GTX, là encore comme le veut la théorie, ce qui est décevant : on reste ainsi au même niveau que la X1950 XTX, et au niveau du nombre de ROP, que la X800XT !
En revanche, alors que la GeForce 8 parvient en pratique à multiplier par 5 son fillrate dans les passes Z, la HD 2900 XT ne parvient qu’à le doubler, même si c’est une première pour AMD !
L’interface mémoire
Terminons ce tour d’horizon du R600 en jetant un coup d’œil à l’interface mémoire. AMD a évidemment repris le fameux bus en anneau de sa gamme X1000, mais sa largeur a été augmentée : désormais le bus fait 1024 bits (512 bits en lecture, 512 en écriture). Le mode de fonctionnement a aussi été modifié : auparavant les “clients” du contrôleur mémoire envoyaient leurs requêtes a un contrôleur central qui déterminait, en fonction de la position de la donnée en mémoire, à quel ring stop transférer la commande. Désormais le contrôleur central a disparu. Les clients s’adressent directement à leur ring stop dédié et si la donnée réclamée n’est pas disponible à ce ring stop elle est transféré à celui qui la détient. Cette architecture complètement distribuée est donc encore plus évolutive que celle introduite avec les Radeon X1000.
Antialiasing : 8X et CFAA
Quoi de neuf du côté de l’antialiasing ? On note l’apparition d’un mode 8X multisampling, là encore comme sur le G80 : intéressant pour les anciens jeux, a priori inexploitable sur tous les titres un tant soit peu gourmand. Sauf qu’il se fait au détriment du mode 6X, qui disparaît complètement, ce qui est regrettable, ce mode offrant souvent un bon compromis dans les anciens jeux sans avoir à passer au très gourmand 8X !
Rien d’autres ? Si, là où NVIDIA propose son CSAA, AMD introduit lui son CFAA pour Custom Filter AntiAliasing.
Le CFAA permet plusieurs choses :
- Récupérer des samples en dehors du pixel traité
- Utiliser des pondérations non uniformes pour chaque sample
- Utiliser des filtres qui s’adaptent aux caractéristiques du pixel
Ainsi AMD introduit plusieurs nouveaux modes d’antialiasing en utilisant ces capacités. Le mode 12X par exemple récupère des échantillons en dehors du pixel (1 pour chaque pixel situé au dessus, à gauche, en bas et à droite) et les filtres en utilisant non plus un filtre boîte habituel (qui attribue une pondération identique à tous les échantillons), mais un filtre triangulaire qui attribue un poids plus important aux échantillons les plus proches du centre du pixel. Sans aller jusqu’à faire un cours de traitement du signal, les schémas suivant illustrent bien la différence de qualité de reconstruction obtenue en utilisant un filtre triangulaire par rapport au filtre boîte.

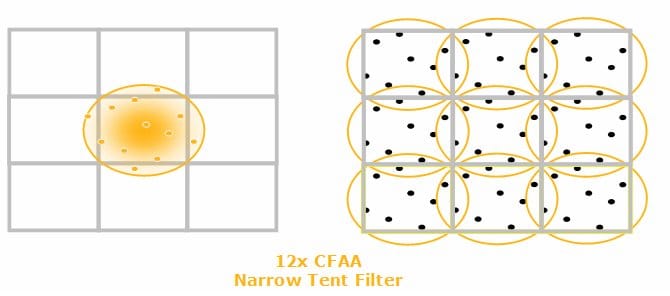
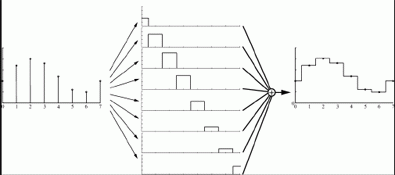
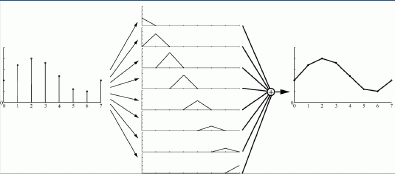
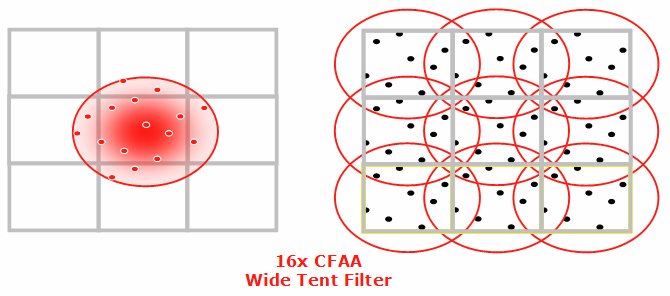
La contrepartie de ce type de filtre est que plus on élargit le noyau, plus on introduit de flou dans l’image. Pour compenser ce problème AMD introduit un troisième mode : le mode 24X qui consiste en deux passes. En premier lieu une passe de détection des contours est effectuée et en second lieu le filtrage est adapté par pixel en fonction de leur position :
- s’ils sont sur un contour, de nombreux échantillons et un filtre de haute qualité sont utilisés
- s’ils ne sont pas sur un contour, moins d’échantillons et un simple filtre boîte sont utilisés
Evidemment la passe de détection de contour n’est pas gratuite, donc ce filtre aura un coût plus important que les autres, mais sur les anciens jeux où le GPU aura de la puissance à revendre, il devrait constituer un plus appréciable.
Antialiasing : en pratique, filtrage anisotropique
En pratique, voici comment ces options sont proposés à l’utilisateur dans le Catalyst Control Center :
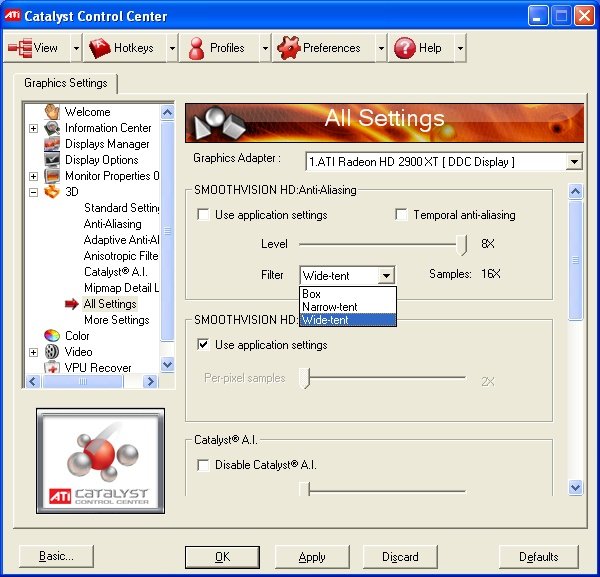
Et voici les trois niveaux d’antialiasing désormais proposés par chacune des cartes :
Voyons maintenant l’impact de l’antialiasing sur un cas particulier assez gourmand, F.E.A.R. Combat (1600*1200, antialiasing activé dans le jeu et donc limité à 4X) :
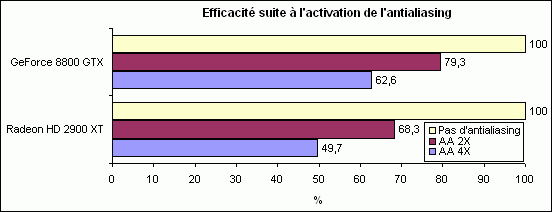
Sous ce jeu, la HD 2900 XT paye le plus lourd tribut suite à l’activation de l’antialiasing. N’oublions pas qu’elle ne dispose que des deux tiers de la quantité de mémoire de la 8800 GTX (mais d’un meilleur débit). A noter qu’à titre de comparaison, sous Oblivion les pourcentages remontent à 89,6 % (AA 2X) et 84,1 % (AA 4X) avec la 8800 GTX.
Nous reviendrons bien sûr sur les performances et la qualité visuelle de l’antialiasing dans les jeux.
Filtrage anisotropique
Côté filtrage anisotropique, bien que seul nVidia devait se défaire de la mauvaise réputation en la matière de sa précédente génération, il l’a si bien fait avec la GeForce 8 que le filtrage de cette dernière est devenue une référence, supérieure à celle par défaut sur Radeon X1000. Du coup, AMD réplique en faisant du filtrage anisotropique de haute qualité des Radeon X1000 (disponible uniquement après activation dans les drivers), le réglage par défaut sur Radeon X2000. Du coup la qualité est vraiment proche entre les deux architectures, mais semble un rien en faveur des GeForce 8. Nous étudierons plus en détail la qualité visuelle du filtrage par défaut des deux cartes dans les jeux, et vous pourrez d’ailleurs vous faire votre propre opinion sur le sujet.
Voyons ce qu’il en est des performances, toujours sous F.E.A.R. Combat en 1600*1200 (filtrage appliqué via le jeu).
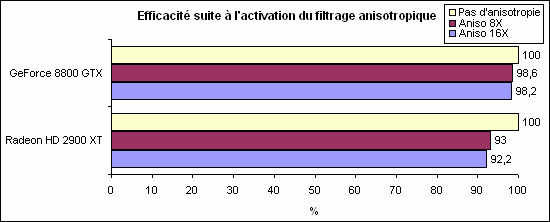
Ici aussi la Radeon HD 2900 XT souffre bien plus de l’application du filtrage anisotropique, même si évidemment l’activation de ce filtre est devenue négligeable en termes de performances sur les cartes haut de gamme actuelles, malgré l’amélioration de la qualité (donc de la gourmandise) des algorithmes. A titre de comparaison là encore, sur un jeu ayant bien plus recours aux textures (Oblivion), les pourcentages passent toutefois à 90,6 % (anisotropie 8X) et 89,7 % (anisotropie 16X) avec la 8800 GTX. Ce faible écart traduit bien la faible différence de qualité visuelle entre ces 2 modes :
Vidéo ? HD !
Le R600 est donc l’occasion pour AMD d’opérer un petit lifting dans le nom commercial de ses cartes, avec l’introduction du mot clef “HD” dans le nom de la Radeon HD 2900 XT, histoire de bien mettre en avant les deux lettres à la mode actuellement…
La vidéo est cependant un des points de distinction et de supériorité de la Radeon HD 2900 XT sur ses concurrentes, les GeForce 8800. Elle introduit en effet, l’UVD, un décodeur vidéo unifié qui est donc une unité spécialisée au décodage des vidéo bien qu’il soit physiquement présent au sein du GPU.
Comme nous l’avons vu, l’AVIVO ne prend en charge qu’une partie des étapes du décodage des formats HD. En particulier, il n’est pas à même d’accélérer l’entropy decode, pourtant l’étape la plus gourmande mais particulièrement peu propice aux algorithmes de prédiction de données du CPU, comme à la parallélisation pourtant nécessaire afin d’obtenir de bonnes performances sur un GPU.
C’est cette étape qu’est parvenu à franchir AMD grâce à son UVD, supportant l’AVIVO HD. Ce qui est important à noter, c’est que contrairement au PureVidéo 2 qui a fait son apparition sur les GeForce 8600/8500, et qui parvient également à prendre en charge l’entreopy decode, l’UVD parvient à le faire à la fois pour H.264 et pour le VC-1, le format fréquemment utilisé actuellement sur les HD DVD.
Toutefois, il ne faut pas perdre du vu qu’en ce qui concerne les GeForce 8800, le retard est bien plus grand puisqu’elle en restent au Purevidéo HD qui ne prend en charge que 2 étapes sur 4. Selon AMD, l’utilisation processeur lors de la lecture du HD DVD Yozakura sur un Code 2 Duo 2 GHz passerait de 64 % (décodage via le GPU) à 12 % (UVD), ce que nous étudierons plus en détail dans un prochain article.
MAJ : Contrairement à ce que nous venons d’affirmer et ce qu’AMD laissait clairement entendre, l’UVD n’est pas implémenté dans la Radeon HD 2900 XT mais uniquement dans les 2600 et 2400 ! Carton rouge au constructeur pour ce manque de clarté évident.
Autre innovation, le GPU intègre également un décodeur audio, loin de faire office de carte son cependant. Le but ? Faire transiter le signal vidéo et son via la sortie HDMI (qui s’obtient via un adaptateur DVI -> HDMI spécial, le seul à pouvoir faire transiter le son, les HD 2900 XT étant dotées de deux sorties DVI uniquement), sans avoir à utiliser un câble pour relier la sortie S/PDIF de la carte son ou de la carte mère à la carte graphique. Outre le problème pratique et esthétique que cela pose, il faut en effet savoir que la certification Vista Premium sur les systèmes dotés de sortie HDMI stipule que le signal audio ne doit pas pouvoir être splité. En clair, cela veut dire que dans le cas d’un simple contrôleur audio intégré sur la carte mère, il n’est plus possible d’avoir d’un côté le signal HDMI avec la vidéo et son signal sonore, et de bénéficier du son système par ailleurs. Seul regret : le support se limite au HDMI 1.2 (pas de flux 1080p géré au delà de 24 Hz ni de Dolby TrueHD notamment) !
La Radeon HD 2900 XT
La HD 2900 XT est une carte imposante. Pas de doute possible, on est bien en présence d’une carte haut de gamme ! Toutefois, il faut signaler que sa taille reste inférieure de 2,5 cm à celle de GeForce 8800 GTX, avec “seulement” 24 cm pour le PCB. Ce sera pourtant le seul argument en sa faveur. Côté poids, la bête frise en effet le kilo avec 936 g (contre 737 g pour la 8800 GTX) : attention donc à la robustesse des systèmes de fixation rapides des boîtiers au niveau des cartes filles ! A l’origine de ce poids ? Le radiateur entièrement en cuivre, là ou celui de la 8800 GTX parvient à se contenter d’aluminium et d’une longueur un peu plus contenue. Les points communs entre les deux ventirads ne manquent cependant pas, avec la présence de 2 heatpipes afin de répartir la chaleur au mieux, mais également un ventilateur assez proche, de type radial et de 7,5 cm de diamètre. Cela est donc de bon augure concernant la nuisance sonore de la carte…
Pourtant, un dernier point attire l’attention : l’alimentation de la carte. Très loin de se satisfaire des 75 W transmis par le connecteur PCI Express 16x, la carte dispose en effet de 2 connecteurs supplémentaires. Mais là où nous n’avions à faire qu’à 2 connecteurs 6 pins (“PCI Express”), sur la 8800 GTX, ici un de ces 2 connecteurs intègre 8 pins, le connecteur DXX, présent afin de satisfaire la norme PCI Express 2.0. Heureusement, cette carte n’a posée aucun problème, en fonctionnement comme en overclocking, avec 2 connecteurs 6 pins classiques, ce connecteur restant physiquement compatible avec le DXX.
| GPU | 8800 GTX | HD 2900 XT | X1950 XTX |
|---|---|---|---|
| Fréquence GPU | 575 MHz | 742 MHz | 650 MHz |
| Fréquence shaders | 1350 MHz | 742 MHz | 650 MHz |
| Fréquence mémoire | 900 MHz | 825 MHz | 1000 MHz |
| Largeur bus mémoire | 384 bits | 2 x 512 bits | 2 x 256 bits |
| Type de mémoire | GDDR3 | GDDR3 | GDDR4 |
| Quantité de mémoire | 768 Mo | 512 Mo | 512 Mo |
| Nombre de pixel pipelines | (32) | (80) | 48 |
| Nombre d’unités de Texturing | 32 | 16 | 16 |
| Nombre de processeurs de vertex | (32) | (80) | 8 |
| Fillrate théorique | (43200 MPixels) | (59360 MPixels) | 31200 MPixels |
| Bande passante mémoire | 86,4 Go/s | 105,6 Go/s | 64 Go/s |
| Nombre de transistors | 681 millions | 700 millions | 384 millions |
| Process | 0.09µ | 0.08µ HS | 0.09µ |
| Surface du die | 484 mm² | 420 mm² | 351 mm² |
| Génération | 2006 | 2007 | 2006 |
| Shader Model supporté | 4.0 | 4.0 | 3.0 |
Nous l’avons vu précédemment, nous ne reviendrons donc pas dessus, mais les spécifications de cette carte restent impressionnantes au niveau du bus mémoire 512 bits et du nombre de streaming processors. Mais pas de la quantité de mémoire, qui n’évolue pas par rapport à la précédente X1950 XTX. Cet indice, couplé à la dénomination de la carte (XT et non XTX), confirment le fait qu’elle ne constitue pas réellement la vrai carte très haut de gamme qu’AMD aurait voulu lancer ce jour. Reste maintenant à déterminer, à l’aide des performances de la HD 2900 XT, si cette annulation a pour cause l’impossibilité d’atteindre les performances de la 8800 GTX ou bien la volonté de proposer une carte à l’excellent rapport qualité/prix comme le prétend AMD.
Du côté du nombre de transistors, AMD avance un très rond 700 millions, probablement arrondit de façon à pouvoir être juste au-dessus de celui du G80. Les deux puces sont donc similaires sur ce plan, ce qui n’était pourtant pas si prévisible (on aurait pu penser à un nombre encore plus grand pour le R600 vu son architecture).
En revanche, le vrai avantage d’AMD repose sur la finesse de gravure : ce dernier à visiblement mis à profit les 6 mois de retard sur son concurrent afin d’utiliser le process 80HS de TSMC, en 0.08µ donc. Il s’agit du deuxième process de ce type pour le fondeur, HS signifiant high speed et restant le plus performant actuellement, les autres process étant comment souvent surtout optimisés au niveau de la consommation. Cet avantage n’est évidemment pas vain, avec un gain en surface et en coût de production de l’ordre de 20 % par rapport au 0.09µ. En pratique, le R600 s’avère 13 % plus petit que le G80, mais reste cependant un monstre !
Le test
Bien qu’AMD insiste sur l’importance de Windows Vista, nous avons effectués l’ensemble des tests DirectX 9 sous Windows XP, cette plateforme restant globalement encore la plus performante pour cela et surtout, seule une petite partie d’entre vous avez migré sous Vista. Evidemment, les tests DirectX 10 n’ont pu l’être que sous ce dernier système. Pas d’autres changements depuis le test des GeForce 8600.
A noter que nous avons cependant tenu à comparer la qualité d’image sous chaque jeu, en 1600*1200 + filtres (sauf pour Stalker), à l’aide d’une comparaison visuelle entre captures d’écran prises avec chaque carte. Ceci afin de déterminer quelle carte produit le meilleur rendu.
Attention, la GeForce 8800 GTS 320 Mo que nous avons utilisée pour ce test à titre de référence correspond au modèle overclocké MSI HD OC. Avec ses fréquences supérieures (+15 % pour le GPU, + 6 % pour la mémoire), il s’avère donc logiquement environ 10 % plus performant que la GeForce 8800 GTS 640 Mo en “basses” résolutions dans nos tests. A noter que son prix est pourtant identique à la version standard de la marque actuellement (320 €), et permettra à ceux qui hésitent entre une 8800 GTS 640 Mo, une 8800 GTS 320 Mo overclocké, la X1950 XTX et la Radeon HD 2900 XT de se faire une idée.
Configuration de test :
- Intel Core 2 Extreme QX6700 (quad-core 2.66 GHz)
- Intel Bad Axe 2 (D975XBX2)
- 2 x 1 Go DDR-2 800 MHz 4-4-4-12 Crucial
- Hitachi T7K250 250 Go + WD Raptor 74 Go
- Creative Audigy 4 Pro
- Lecteur DVD Asus 12x
- Tagan U15 530 W
Drivers utilisés :
- ForceWare 158.22 (GeForce 8 et Windows XP)
- Catalyst 7.4 WHQL (Radeon X1950 XTX et Windows XP)
- Catalyst beta 8-37-4-070419a (Radeon HD 2900 XT et Windows XP)
- ForceWare 158.42 (GeForce 8 et Windows Vista 32 bits)
- Catalyst 8-37-4-070419a (Radeon HD 2900 XT et Windows Vista 32 bits)
Test Drive Unlimited, Supreme Commander
Test Drive Unlimited
Sur ce premier jeu, la HD 2900 XT termine à un cheveu derrière la 8800 GTX (qui reste entre 2 et 6 % plus rapide), sauf en 1600*1200 ou elle est distancée plus nettement. En revanche, son avance sur la 8800 GTS 640 Mo est nette : 28 % hors filtres, et jusqu’à 66 % une fois les filtres activés.
Supreme Commander
Sup com affiche pour sa part une préférence nettement plus marquée pour la GeForce 8800 GTX (25 à 46 % plus rapide que la carte AMD). Ici, la HD 2900 XT est en fait au coude à coude avec la 8800 GTS 640 Mo, légèrement devant hors filtres et, à l’opposé de Test Drive Unlimited, derrière une fois l’antialiasing activé.
Age of Empires 3, Oblivion
Age of Empires 3
Résultat assez proche donc entre Age of Empires III et Supreme Commnader : très gourmand en pixel shading, ce test ne laisse aucune chance à la HD 2900 XT comparativement à la 8800 GTX, conformément à ce que nos tests synthétiques nous ont permis de voir. D’ailleurs ici, la 8800 GTS 320 Mo overclockée devance la 640 Mo : les 320 Mo de mémoire suplémentaires ne parviennent à s’exprimer qu’en 2048*1536 + filtres, mais même dans ce cas la 2900 XT reste légèrement devant.
The Elder Scrolls IV : Oblivion
Sous Oblivion, les performances de la HD 2900 XT sont quasiment identiques à celles de la 8800 GTS 640 Mo hors filtres. En 1600*1200 + antialiasing, elle prend largement l’avantage mais curieusement (ou plus vraisemblablement limitée par ses 512 Mo de mémoire), retombe derrière sa rivale en 2048*1536 + filtres.
FEAR, Gothic 3
F.E.A.R. Combat
A la peine hors filtres (inférieure à toutes les GeForce 8800 en 1600*1200 notamment), la HD 2900 XT parvient à inverser la vapeur une fois l’antialiasing activé, puisqu’elle se révèle alors plus performante que la 8800 GTX ! Une situation bien rare cependant, mais qui illustre la plus grande homogénéité de performance des cartes AMD (et qui était également sensible sur la dernière génération), ce qui suivant la résolution leur porte préjudice ou les met en avant. Reste que les 8800 GTS sont moins intéressantes ici que la nouvelle carte AMD.
Gothic 3
Au contraire, sur Gothic 3 la Radeon 2900 XT est la carte sur laquelle les performances variant le plus suivant la résolution. Très performante en 1600*1200, elle encaisse mal l’activation des filtres avec jusqu’à 10 % de performances en moins par rapport à la GeForce 8800 GTS 640 Mo. A noter que ce n’est pas sa quantité de mémoire qui est en cause à priori, vu la supériorité dans ce test de la 8800 GTS 320 Mo sur sa grande sœur…
STALKER
STALKER
Sous STALKER, que nous avons exécuté sans antialiasing encore une fois (vu son très faible impact visuel et le niveau de performance déjà assez faible des cartes actuelles alors que toutes les options ne sont pas à fond), la HD 2900 XT obtient son pire résultat, bien qu’elle ne soit la encore que d’un cheveu inférieure à la GeForce 8800 GTS 640 Mo (-3 %). Il faut noter qu’elle n’est cependant que 21 à 27 % plus performante que la précédente génération, la X1950 XTX : on attendant tout de même mieux !
Tests DirectX 10
A défaut d’avoir eut le temps de développer nos propres tests synthétiques DirectX 10, nous allons dans un premier temps utilisé des exemples issus du SDK de DirectX 10, ainsi que le jeu Call of Juarez, un western plutôt honnête, en version DirectX 10 (le tout premier). AMD nous a bien sûr conseillé d’utiliser ses propres tests synthétiques, mettant en avant les n-patches et l’illumination globale en utilisant les Geometry Shaders, et qui bien sûr étaient au minimum 30 fois plus rapides sur la HD 2900 XT que sur la 8800 GTX…
Content Streaming
Ce premier exemple consiste à charger du contenu en streaming afin de pouvoir en afficher plus que ce peut contenir la mémoire vidéo ou la RAM. Utilisé en mode load everything (seul mode réellement Direct3D 10), il utilise la spécificité du modèle de driver de Windows Vista permettant de transformer la RAM en mémoire virtuelle pour la carte graphique.

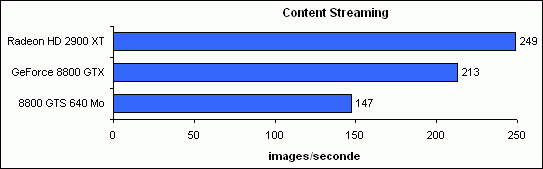
Ce test mettant notamment en avant la maturité des drivers pour Windows Vista affiche une nette supériorité pour la Radeon HD 2900 XT, 17 % devant la 8800 GTX et 69 % plus performante que la 8800 GTS 640 Mo.
Soft Particules
Voyons maintenant la génération d’un effet volumétrique via système de particules pour représenter de la fumée.

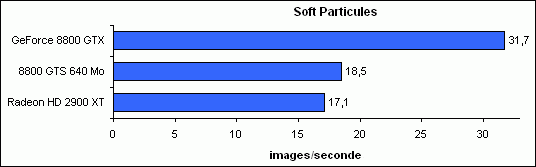
La 2900 XT s’effondre ici par rapport à la 8800 GTX, et revient à un niveau très proche de la 8800 GTS 640 Mo (-8 %), comme sous les jeux Direct3D 9 donc.
Displacement Mapping 10
Les Geometry Shaders sont ici utilisés afin d’extruder des prismes qui sont ensuite décomposés en 3 tétraèdres pour chaque triangle. Un pixel shader est ensuite utilisé pour effectuer un raytracing.

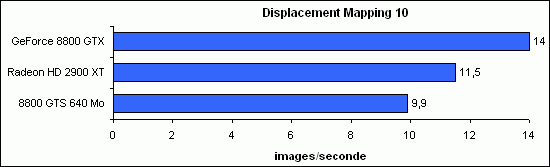
Traditionnellement puissante dès lors qu’il s’agit d’utiliser les Geometry Shaders, la HD 2900 XT repasse ici devant la 8800 GTS sans parvenir à rattraper la 8800 GTX, 22 % plus performante.
Tests DirectX 10 (suite)
Skinning 10
Cet example effectue donc un skinning en Direct3D 10, en utilisant le Stream Out sans les Geometry Shaders.
La 2900 XT ne peut plus lutter ici contre la 8800 GTS (-9 %).
HDR Formats 10
Cet exemple est initialement destiné à montrer comme des données HDR peuvent être compressées dans des formats d’entiers par compatibilité. Il donne cependant accès à un large choix de formats de compression et de modes de rendu.
Ce test un peu particulier place la 8800 GTX deux fois plus performante que la 2900 XT. Ce résultat est sans doute à imputer au fait que seule la 5ème ALU de chaque unité peut effectuer une normalisation.
CubeMapGS
Cet exemple utilise deux fonctionnalités propres à Direct3D 10 : les render target array et les Geometry Shaders, afin de rendre une texture cubique.
Un peu plus surprenant, la 2900 XT s’effondre ici aussi face aux GeForce 8.
Test DirectX 10 (fin, Call of Juarez)
Instancing 10
Cet exemple utilise l’instancing et les texture arrays afin de réduire le nombre de requêtes nécessaire au rendu d’une scène complexe, ainsi que l’AlphaToCoverage.

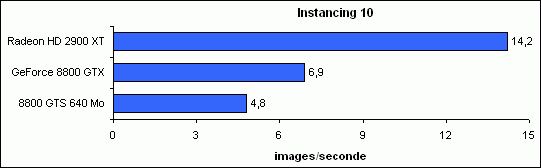
Retournement de situation ici avec une excellente performance de la 2900 XT comparativement à la 8800 GTX, et plus encore bien sûr face à la GTS (3 fois moins performante).
Particule GS
Ce feu d’artifice est obtenu via un système de particule complet utilisant les Geometry Shaders, le Stream Output et DrawAuto.
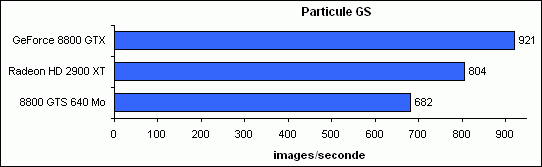
Si la 2900 XT reste ici devant la 8800 GTS, elle repasse cependant derrière la GTX (-13 %).
Call of Juarez
Voici enfin les performances que nous avons obtenu sous la démo du jeu Call of Juarez en version DirectX 10.

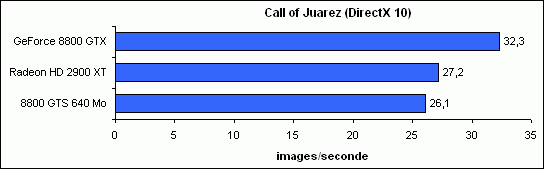
Au final, le résultat reste assez proche de celui obtenu en moyenne sous les jeux DirectX 9, avec une GeForce 8800 GTX assez nettement en tête (+19 %), et une 2900 XT au coude à coude avec la 8800 GTS, bien que devant ici (+4 %). Une constation à l’issu de ces tests est qu’aucune des deux architectures GPU actuelles ne semble similaire à celle de la GeForce FX en son temps, à savoir s’avérer très performante sur les jeux Direct3D 9 (8 pour les FX) mais s’effondrer à moins de lourdes optimisations des drivers sous Direct3D 10 (9 pour les FX), ce qui est dans tous les cas une bonne chose !
Consommation, bruit, overclocking
Consommation
Nécessitant en théorie un nouveau connecteur d’alimentation, la HD 2900 XT pourrait pourtant en théorie consommer un peu moins que la GeForce 8800 GTX : nombre de transistors similaire, fréquence à peine plus élevée pour le GPU et beaucoup moins élevée pour les streaming processors, et surtout gravure en 0.08µ et non en 0.09µ.
Consommant très légèrement moins que la 8800 GTX au repos, la HD 2900 XT atteint en revanche un nouveau record de consommation en charge, malgré la présence de “seulement” 512 Mo de mémoire (contre 768 Mo sur la 8800 GTX), et malgré ce que nous venons de dire précédemment donc. Du coup, une alimentation de 450 W de qualité paraît être le minimum pour toute configuration intégrant cette carte.
Nuisance sonore
Le ventirad de la HD 2900 XT va donc avoir bien plus de travail que celui de 8800 GTX. Malgré cela, leur conception identique nous permettait d’être plutôt confiant quand au bruit de la nouvelle carte, jusqu’à ce que nous la branchions.
Silencieuse au repos, la HD 2900 XT montre là encore un tout autre visage dès qu’une application 3D est lancée (son ventilateur n’étant pas thermorégulé, à l’inverse de la X1950 XTX et de ce que la logique voudrait) : le ventilateur accélère alors directement pour atteindre, objectivement, le niveau sonore le plus élevé des cartes testées ! En pratique, il faut toutefois remarquer que seul le bruit de souffle se fait entendre, et non celui potentiellement aigu/grave de la rotation du ventilateur. Il n’empêche, la supériorité des GeForce 8800 reste totale sur ce point !
Overclocking
A l’aide d’AMD GPU Clock Tool, nous avons pu, non sans surprise, atteindre un overclocking significatif. Nous sommes ainsi passé de 743/828 MHz à 870/1050 MHz, soit 17 % de gain sur le GPU et 27 % concernant la mémoire. Sous Oblivion en 2048*1536, le gain atteint ainsi 16 %, ce qui est plus que ce que nous attendions de la carte graphique haut de gamme d’AMD, consommant déjà beaucoup. Preuve que le GPU ne semble pas avoir été poussé à sa limite, ce qui n’aurait de toute façon pas suffit à battre la 8800 GTX. A noter que nous n’avons visiblement pas été limités par l’absence de connecteur DXX (8 pins).
Conclusion
Alors, la Radeon HD 2900 XT est-elle la révolution ou un pétard mouillé ? Ni l’un ni l’autre. On ne peut pas parler de révolution car la plupart des éléments nouveaux introduits par ce GPU nous étaient déjà familiers avec le Xenos, le R5x0 voire même le G80. De plus avec DirectX 10 qui impose des contraintes très précises aux fabricants de GPU, difficile pour AMD et NVIDIA de se différencier au niveau des fonctionnalités supportées. L’unité de tesselation est intéressante mais ce ne serait pas la première fois qu’une technique de ce type soit inutilisée en attendant une uniformisation entre les deux rivaux, qui apparaît toutefois inévitable vu le futur DirectX 10.1.
L’architecture du R600 est donc solide car elle repose sur l’évolution de deux architectures ayant fait leurs preuves, et de plus elle paraît très évolutive. En revanche on peut regretter certains choix un peu frileux d’AMD par exemple au niveau du nombre d’unités de textures ou de ROP. Là où NVIDIA dispose de 32 unités de textures et de 24 ROP avec moins de bande passante, AMD reste désespérément figé à 16. Si ce choix se comprenait du temps des bus 256 bits on attendait mieux de la première architecture à bus 512 bits.
Sur un plan plus terre-à-terre, la Radeon HD 2900 XT n’est de toute évidence pas la carte très haut de gamme que nous attendions, celle que se doit de sortir tout constructeur pour accompagner le lancement de sa nouvelle architecture et lui apporter l’assise propre au fameux titre de “Carte 3D la plus performante”. AMD n’avait pas assez de réserve pour aller aussi loin au niveau des fréquences et des performances que nVidia. Une fois ceci dit, il faut cependant reconnaître qu’à 400 € et si sa disponibilité annoncée comme immédiate se vérifie, la Radeon HX 2900 XT dispose de solides performances qui la place environ 10 à 20 % au-dessus de la GeForce 8800 GTS 640 Mo. Intéressant face à cette dernière, un peu moins face à la 8800 GTS 320 Mo qui reste presque aussi performante que sa grande sœur mais que l’on commence à trouver à 280 €. Il est par ailleurs à noter que bien que l’on en soit encore qu’aux prémisses des applications/jeux DirectX 10, cette API ne semble pas beaucoup modifier la donne côté hiérarchie.

Quand aux déclinaisons de milieu et d’entrée de gamme, devant pourtant être lancées simultanément (ce qui constituait d’ailleurs la principale excuse du constructeur pour justifier son retard il y a 2 mois), elles ne verront pas le jour avant début juillet au mieux, trahissant manifestement de nouveaux problèmes de production.
Avec le R580 AMD avait su corriger un défaut important du R520, la puissance de calcul, espérons que l’évolution du R600 suive le même chemin !
- Les plus
- Les moins
- Architecture solide
- Performances supérieures aux GeForce 8800 GTS
- Puissance sur les vertex shaders
- Bus mémoire 512 bits et gravure en 0.08µ
- HL : Episode 2, Team Fortress 2 et vrai adaptateur DVI -> HDMI (audio) inclus
- Performances avec les Geometry Shaders (DX10)
- Performances inférieures à la 8800 GTX
- Prix nettement supérieur à la GeForce 8800 GTS 320 Mo
- Carte bruyante en 3D
- Consommation supérieure à la 8800 GTX en charge
- Plus d’antialiasing 6X
Recapitulatif des performances sous les jeux DirectX 9
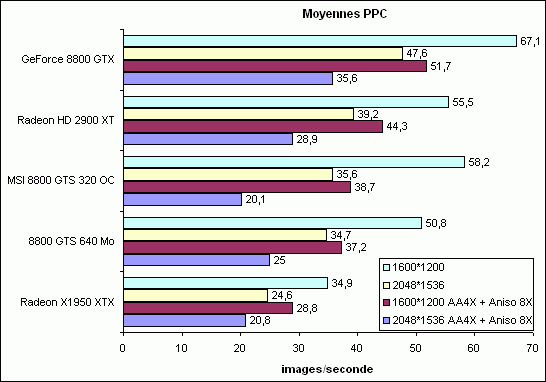
A noter que les moyennes une fois antialiasing activé excluent donc le jeu STALKER, et que par ailleurs elles ne reprennent pas les résultats obtenus sous DirectX 10.









