Voici donc les derniers nés de l’histoire des GPU NVIDIA, une saga qui dure depuis le tout premier NV1 lancé il y a… 28 ans ! Après la génération Pascal, voici la génération Turing, l’architecture Volta ne s’adressant pas aux joueurs. NVIDIA présente Tu
NVIDIA Turing : une ray-volution ?
Voici donc les derniers nés de l’histoire des GPU NVIDIA, une saga qui dure depuis le tout premier NV1 lancé il y a… 23 ans ! Après la génération Pascal, voici la génération Turing, l’architecture Volta ne s’adressant pas aux joueurs. NVIDIA présente Turing comme une petite révolution pour le rendu 3D en temps réel des jeux vidéo : c’est le premier GPU du genre à intégrer des coeurs dédiés à l’intelligence artificielle (Tensor) et surtout au ray tracing (RT). De quoi améliorer considérablement la qualité du rendu 3D en assistant les traditionnels coeurs CUDA.
« La plus grande avancée depuis 10 ans »
Selon NVIDIA, il s’agit du plus grand bond en avant technique depuis une dizaine d’années. Le géant du GPU explique d’ailleurs que les coeurs RT sont le résultat de 10 ans de recherche, depuis l’ambition du ray tracing en temps réel avancée par NVIDIA en 2008.
Pour l’instant, il est impossible d’en dire plus sur les performances pratiques de ces cartes. Nos testeurs viennent tout juste de recevoir les cartes et les pilotes adaptés. Notez d’ailleurs que les premiers tests des GeForce RTX 2080 Ti et 2080, publiés le 19 septembre, ne montreront pas les performances avec les technos RTX et l’assistance des coeurs Tensor, faute de jeu pour l’exploiter. On en saura toutefois plus sur les capacités de ces cartes dans un rendu classique par rastérisation.
Pour l’instant donc, voici tout ce qu’il faut savoir sur l’architecture Turing : fonctionnement, apports, promesses, et caractéristiques précises. Notez que nous avons déjà parlé de Ansel RTX, et de toutes les démos vidéo à voir à l’annonce des cartes.
Caractéristiques complètes des cartes :
| Modèle | Quadro RTX 6000 | GeForce RTX 2080 Ti Founders Edition | Quadro RTX 5000 | GeForce RTX 2080 Founders Edition | GeForce RTX 2070 Founders Edition |
|---|---|---|---|---|---|
| Architecture GPU | Turing TU102 | Turing TU102 | Turing TU104 | Turing TU104 | Turing TU106 |
| GPCs | 6 | 6 | 6 | 6 | 3 |
| TPCs | 36 | 34 | 24 | 23 | 18 |
| SMs | 72 | 68 | 48 | 46 | 36 |
| Coeurs CUDA par SM | 164 | 64 | 64 | 64 | 64 |
| Coeurs CUDA par GPU | 4608 | 4352 | 3072 | 2944 | 2304 |
| Coeurs Tensor par SM | 8 | 8 | 8 | 8 | 8 |
| Coeurs Tensor par GPU | 576 | 544 | 384 | 368 | 288 |
| Coeurs RT | 72 | 68 | 48 | 46 | 36 |
| Fréquence GPU Base (Boost) | 1455 MHz 1770 MHz | 1350 MHz 1635 MHz | 1620 MHz 1815 MHz | 1515 MHz 1800 MHz | 1410 MHz 1710 MHz |
| RTX-OPS (Tera-OPS) | 84 | 78 | 62 | 60 | 45 |
| Rays Cast (Giga Rays/s) | 10 | 10 | 8 | 8 | 6 |
| FP32 TFLOPS | 16,3 | 14,2 | 11,2 | 10,6 | 7,9 |
| INT32 TIPS | 16,3 | 14,2 | 11,2 | 10,6 | 7,9 |
| FP16 TFLOPS | 32,6 | 28,5 | 22,3 | 21,2 | 15,8 |
| FP16 Tensor TFLOPS avec FP16 Accumulate | 130,5 | 113,8 | 89,2 | 84,8 | 63 |
| FP16 Tensor TFLOPS avec FP32 Accumulate | 130,5 | 56,9 | 89,2 | 42,4 | 31,5 |
| INT8 Tensor TOPS | 261 | 227,7 | 178,4 | 169,6 | 126 |
| INT4 Tensor TOPS | 522 | 455,4 | 356,8 | 339,1 | 252,1 |
| Mémoire | 24576 Mo GDDR6 | 11264 Mo GDDR6 | 16384 Mo GDDR6 | 8192 Mo GDDR6 | 8192 Mo GDDR6 |
| Interface Mémoire | 384-bit | 352-bit | 256-bit | 256-bit | 256-bit |
| Vitesse de transfert | 14 Gb/s | 14 Gb/s | 14 Gb/s | 14 Gb/s | 14 Gb/s |
| Bande Passante VRAM | 672 Go/s | 616 Go/s | 448 Go/s | 448 Go/s | 448 Go/s |
| ROPs | 96 | 88 | 64 | 64 | 64 |
| Unités de texture | 288 | 272 | 192 | 184 | 144 |
| Texel Fill-rate (Gigatexels/s) | 510 | 444,7 | 348 | 331,2 | 246,2 |
| Cache L2 | 6144 Ko | 5632 Ko | 4096 Ko | 4096 Ko | 4096 Ko |
| Total Bancs de registres par SM | 256 Ko | 256 Ko | 256 Ko | 256 Ko | 256 Ko |
| Total Bancs de registres par GPU | 18432 Ko | 17408 Ko | 12288 Ko | 11776 Ko | 9216 Ko |
| TDP | 260 W | 260 W | 230 W | 225 W | 185 W |
| Transistors | 18,6 milliards | 18,6 milliards | 13,6 milliards | 13,6 milliards | 10,8 milliards |
| Taille du die | 754 mm² | 754 mm² | 545 mm² | 545 mm² | 445 mm² |
| Finesse de gravure | 12 nm FFN | 12 nm FFN | 12 nm FFN | 12 nm FFN | 12 nm FFN |
Les GPU TU102, TU104 et TU106 en détail

TU102 : le GPU complet de la Quadro RTX 6000
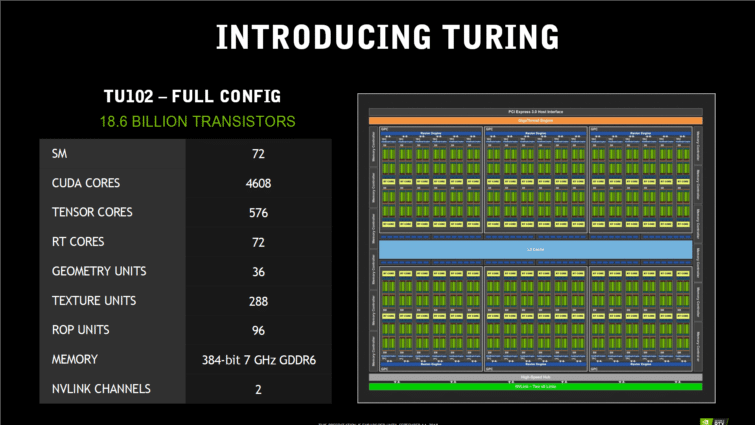
Le TU102 est le GPU Turing le plus puissant, et donc le plus grand (754 mm²), avec 18,6 milliards de transistors gravés par TSMC en 12 nm FinFET. Par rapport à la génération Pascal, la puce est 60 % plus grande, avec 55 % plus de transistors, l’écart est donc assez énorme. Ce n’est pourtant pas le GPU le plus monstrueux de NVIDIA, qui reste le GV100 (Volta), avec 21,1 milliards de transistor sur une surface de 815 mm².
Volta n’est toutefois pas fait pour les joueurs. Un bon exemple : il dispose de 2688 coeurs FP64, 32 par Streaming Multiprocessor (SM), pour le calcul en double précision, indispensable pour certaines applications scientifiques. Pour les jeux, les unités FP64 ne servent à rien, et Turing s’en passe, ou presque : il lui en reste deux par SM, juste pour assurer une compatibilité avec les applications qui l’exigent (mais les performances seront alors divisées par 16 face au FP32).
Un GPU Turing TU102 complet intègre six Graphics Processing Clusters (GPC), composé d’un Raster Engine, de six Texture Processing Clusters (TPC). Chaque TPC intègre deux SM et un Polymorph Engine pour la géométrie. Chaque SM contient 64 coeurs CUDA, 8 coeurs Tensor, un coeur RT, 4 unités de texture, 16 unités load/store pour gérer les registres, 256 Ko de registre, quatre caches d’instructions L0 et un cache L1 de 96 Ko partagé configurable.
Multipliez le tout, et vous obtenez 72 SM, 4608 coeurs CUDA, 576 coeurs Tensor, 72 coeurs RT, 288 unités de texture, et 36 moteurs PolyMorph. Sans oublier l’interface mémoire, composées de 12 contrôleurs GDDR6 32 bits, chacun attaché à un cluster de 8 ROP et 512 Ko de cache L2… Pour un total de 96 ROP sur un bus mémoire 384 bits avec 6 Mo de cache L2.
GeForce RTX 2080 Ti : un TU102 allégé
Pour faire simple : afin de réduire la facture et la consommation, la 2080 Ti sacrifie deux TPC, soit quatre SM. Elle se sépare donc de 256 coeurs CUDA, 32 coeurs Tensor, 4 coeurs RT, 2 moteurs Polymorph, et 16 unités de texture. Un contrôleur mémoire 32 bits est aussi désactivé, pour une largeur agrégée de bus qui tombe donc à 352 bits, avec 8 ROP de moins, et 512 Ko de cache L2 disparus. Et pour cause, il n’y a plus 12 puces mémoire sur le PCB, mais 11.
La carte arbore un TDP de 260 W en version Founders Edition, et pourra descendre à 250 W sur les modèles de référence. Ce qui est étonnant, c’est que la Quadro RTX 6000, avec un GPU plus lourd, arbore aussi un TDP de 260 W, et sa fréquence boost monte bien plus haut (1770 MHz contre 1635 MHz pour la 2080 Ti). Seule explication possible : les GPU d’excellente qualité seront triés pour la Quadro !
TU104 : la version raisonnable
On retrouve des dimensions plus « humaines » avec le TU104, qui laisse place à une RTX 2080 au prix moins délirant. Le nombre de transistor diminue (13,6 milliards), sur une surface de 545 mm²… qui reste supérieure à celle du GPU Pascal GP102 haut de gamme !
Le TU104 garde évidemment la même structure architecturale, à une différence près : les six GPC ne contiennent désormais que 4 TPC au lieu de 6. Du coup, un TU104 complet, celui que la Quadro RTX 5000, regroupe 3072 coeurs CUDA. L’interface mémoire est aussi tronquée, avec huit contrôleurs 32 bits, 64 ROP et 4 Mo de cache L2. Notez que le TU104 voit aussi une connexion NVLink réduite par deux (8x, soit 50 Go/s).
La version destinée à la GTX 2080 est encore un peu tronquée : l’un des TPC du TU104 est désactivé, soit 128 coeurs CUDA et 2 coeurs RT en moins, etc. Attention, la carte est effectivement plus puissante que la GTX 1080, mais elle est aussi plus gourmande en énergie de 45 W.
TU106 : le petit frère
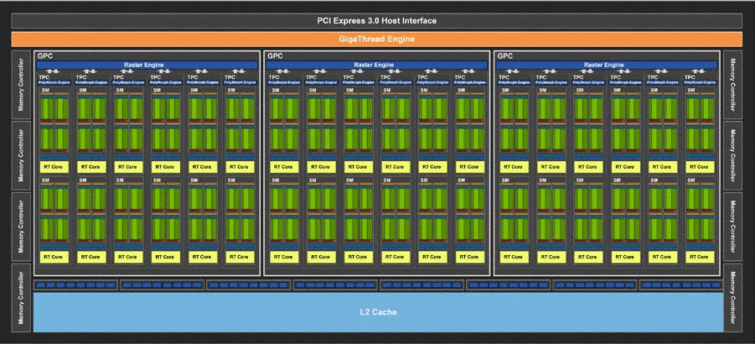
Si le précédent GP106 équipait les GeForce GTX 1060 milieu de gamme, le nouveau TU106 équipe l’entrée du haut de gamme, la RTX 2070. Le GPU est encore plus petit (445 mm²). Il n’intègre plus que 3 GPC contenant 6 TPC chacun, ce qui donne 36 SM et 2304 coeurs CUDA. Il n’y a plus que 36 coeurs RT et 288 coeurs Tensor. Sur le papier, la carte est presque deux fois moins puissante que la RTX 2080 Ti, mais garde une consommation relativement élevée de 185 W dans sa version Founders Edition overclockée, 175 W de référence, alors que la 1070 était à 150 W. Le TU106 perd aussi le NVLink.
Le SM Turing en détail
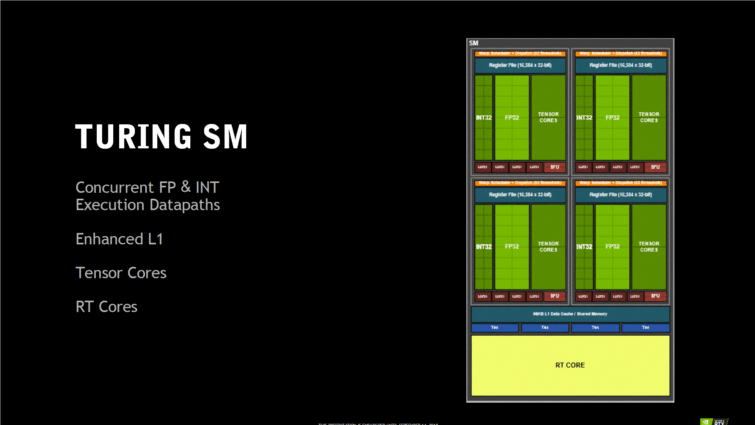
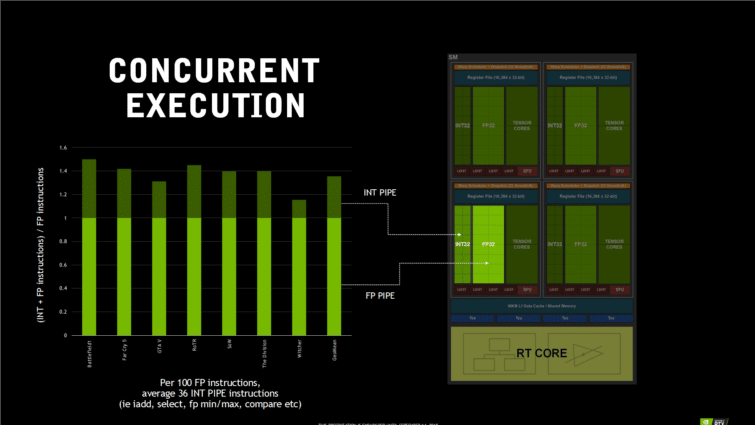
Le Streaming Multiprocessor de Turing est totalement différent du précédent SM de Pascal et ses 128 coeurs CUDA. Il n’embarque plus que 64 coeurs CUDA, mais s’arme de huit coeurs Tensor et d’un coeur RT. Héritage de l’architecture Volta : les Coeurs CUDA ont cette fois la possibilité d’exécuter simultanément des opérations FP32 à virgule flottante et INT32 en nombres entiers, ce qui va profiter grandement aux performances de rendu des jeux classiques en rastérisation, selon NVIDIA.
Le gain potentiel serait assez important pour certain jeux comme Battlefield 1, qui exécute 50 opérations INT32 pour 100 opérations FP32 dans son code de rendu. D’autres jeux sont moins demandeurs en opération INT32, mais NVIDIA affirme qu’environ 36 % des opérations sont du INT32 qui retardent le pipeline FP32, réduisant ainsi les performances si le GPU n’est pas capable de les traiter en parallèle. NVIDIA parlent toujours de 64 coeurs CUDA pour simplifier, mais il y a en fait 64 unités FP32 et 64 unités INT32 dans le SM, pour être exact.
Les SM du précédent GPU Pascal peuvent sembler plus complexes et avancés, mais Turing en embarque deux fois plus, ce qui permet de contenir beaucoup plus de coeurs CUDA, sans compter l’interface mémoire beaucoup plus avancée. S’y ajoutent les capacités d’accélération du coeur RT, que nous allons détailler dans les pages suivantes, et l’assistance des coeurs Tensor. Pour l’instant, NVIDIA ne semble avoir qu’une seule application claire de cette IA : le DLSS, dont nous allons aussi parler dans les pages suivantes.
Turing augmente sa mémoire et améliore sa hiérarchie d’utilisation. Pascal utilisait un cache L1 pour chacun de ses quatre blocs, et une mémoire partagée entre tous les blocs. Les nouveaux SM optent pour un cache L1 unifié et partagé entre leurs quatre blocs. Cette unification permet de stocker toute les tâches dans un cache, quelque soit leur destination (cache L1 ou mémoire partagée dans Pascal), sans ralentir les unités d’exécution.
Ce cache L1 profite aussi d’un bus de donnée bien plus large, doublant sa bande passante (128 octets par cycle d’horloge contre 64 octets chez Pascal). Ce cache peut aussi être configuré en 64 Ko de L1 et 32 Ko de mémoire partagée (ou l’inverse), ce qui rappelle l’architecture Kepler. Le cache L2 du GPU est aussi doublé par rapport au GP102 Pascal, avec une bande passante annoncée « significativement plus importante ».
50 % plus rapide ?
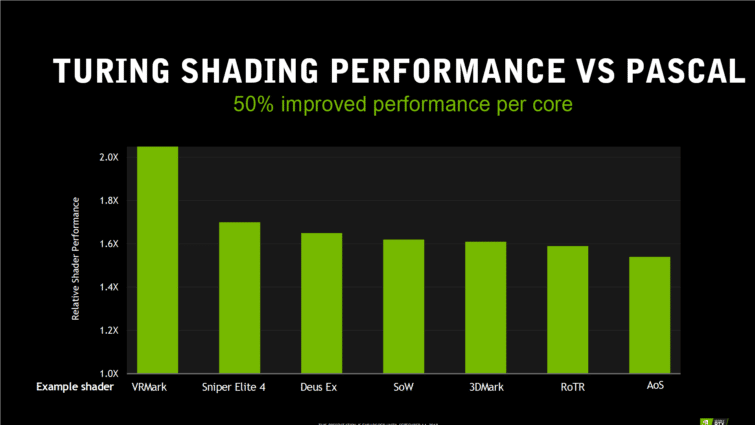
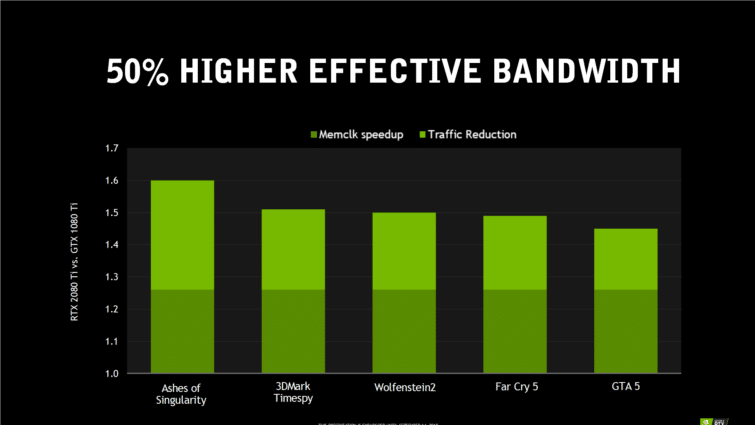
Toutes ces améliorations combinées permettent à NVIDIA d’annoncer 50 % de performance en plus par coeur CUDA, par rapport à Pascal. Et au niveau de la mémoire vidéo, NVIDIA affirme avoir encore perfectionné sont système de compression lancé avec Pascal sur de la RAM GDDR6 plus rapide. La bande passante mémoire est donc nettement supérieure, d’environ 50 % si on cumule les gains de la fréquence mémoire et de la compression.
L’IA au service du rendu 3D

Turing hérite des coeurs Tensor arrivés avec l’architecture Volta, mais dans une version améliorée. Le TU102 intègre toutefois moins de coeurs Tensor que la puce GV100 de la Titan V (576 maximum contre 640). Ils sont aussi différents car ils ne gère pas les calculs vraiment destinés à l’entraînement en Deep Learning, Turing étant plutôt conçu pour exploiter par inférence l’IA d’un réseau neuronal déjà entraîné. Ces coeurs Tensor sont toutefois annoncés très rapides, capables d’atteindre 114 TFLOPS FP16, et jusqu’à 455 TOPS INT4.
Ces coeurs Tensor sont destinés à l’assistance au rendu graphique 3D, mais NVIDIA a suggéré qu’il serait possible de les utiliser dans d’autres domaines, notamment l’intelligence artificielle des personnages dans les jeux vidéo, la reconnaissance et la synthèse vocale, la détection de la triche en jeu, etc.
L’antialiasing intelligent ultime ?
Pour l’instant, la seule application annoncée est le DLSS, pour Deep Learning Super Sampling. La technos doit être gérée par les développeurs via l’API NGX de NVIDIA, mais l’implémentation est annoncée ultra-simple. Après tout, il ne s’agit que d’appliquer par inférence ce qu’a appris un gros réseau neuronal entraîné par NVIDIA sur de multiples images en haute et basse définition. Les modèles entraînés sont ensuite téléchargés via les pilotes graphiques de NVIDIA, et utilisent les coeurs Tensor pour s’appliquer en temps réel à l’image. Selon NVIDIA, ces modèles ne font que quelques mégaoctets.


La question de la qualité réelle du DLSS reste en suspend. L’exemple de NVIDIA sur la démo Infiltrator de Epic sous Unreal Engine est forcément très convaincante, mais le DLSS fonctionnera-t-il aussi bien sur tous les jeux ? Le DLSS est entraîné sur des images échantillonnés 64 fois, ainsi, un DLSS 2x serait aussi efficace qu’un filtre d’antialiasing classique 64x en super-sampling, sans monopoliser les ressources des coeurs CUDA du GPU. Reste à savoir en pratique ce que ça donnera, avec quelle définition d’image, et quels seront les gains réels de performances…

Le RayTracing hybride expliqué
Voilà le coeur de la nouveauté de l’architecture Turing : le ray tracing en temps réel, un Graal que beaucoup de graphistes et joueurs attendent depuis longtemps. Il ne s’agit évidemment pas d’un rendu 100 % en lancée de rayon, mais d’un rendu hybride, qui mélange rastérisation classique pour la majorité du rendu, et ray tracing accéléré en matériel pour les effets de lumières, de reflets et d’ombre.

Les coeurs RT sont en fait des accélérateurs matériel d’une fonction fixe, celle du BVH (Bounding Volume Hierarchy). Cet algorithme permet de structurer et de simplifier les opérations de ray tracing pour les rendre plus efficaces, notamment en réduisant le nombre d’intersections de triangles qui doivent être testées pour calculer la trajectoire finale du rayon. Les calculs BVH existent déjà dans les jeux, dans des volumes très restreints, via l’API D3D12 RayTracing Fallback. Ils prennent énormément de ressources, surtout s’ils doivent être appliqués dans un grand volume. Le calcul monopolise les coeurs programmables du GPU pour tester les intersections des rayons et des triangles. Il est donc impossible de faire tourner ça en temps réel sur un GPU normal pour un grand volume.
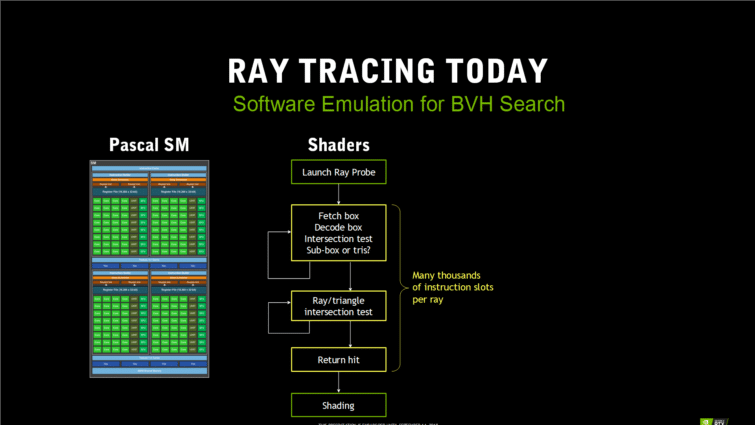
Chez Turing, les coeurs RT accélèrent précisément ces calculs. Le SM lance un rayon dans la scène à tester, et laisse le coeur RT simuler le reste en matériel, sans monopoliser les coeurs CUDA. Ainsi, la GeForce GTX 1080 Ti ne peut générer que 1,1 milliard de rayons par seconde en monopolisant tous ses coeurs CUDA, et la RTX 2080 Ti peut en générer 10 milliards seulement avec ses 68 coeurs RT. Des chiffres qui restent à confirmer, car ils correspondent à des tests spécifiques en ray tracing, et pas à un comportement en jeu.
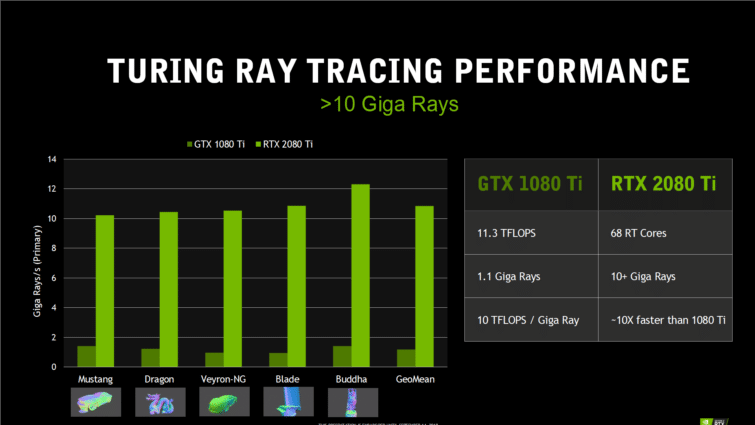
| GeForce GTX 1070 | GeForce GTX 1080 | GeForce GTX 1080 Ti | GeForce RTX 2070 FE | GeForce RTX 2080 FE | GeForce RTX 2080 Ti FE | Quadro RTX 5000 | Quadro RTX 6000 | |
|---|---|---|---|---|---|---|---|---|
| Rays Cast (Giga Rays/sec) | 0,65 | 0,89 | 1,1 | 6 | 8 | 10 | 8 | 10 |
| Cœurs RT | 0 | 0 | 0 | 36 | 46 | 68 | 48 | 72 |
Le ray tracing est ainsi capable de dessiner des ombres quasi-parfaites à l’écran, mais aussi de gérer beaucoup mieux les reflets. Les rayons lancés restant limités, il faudra améliorer artificiellement le résultat par débruitage des ombres, lumières et reflets. Ce débruitage sera logiciel dans la majorité des cas, ce qui va prendre un peu de ressources. NVIDIA a déjà mis au point un système de débruitage matériel par intelligence artificielle, mais n’en parle pas dans ce cas précis. Difficile de savoir pour l’instant si les coeurs Tensor pourront s’en charger. Nous savons que les reflets par ray tracing de Battlefield V sont débruités par un algorithme logiciel. NVIDIA explique toutefois que dans le futur, le débruitage par IA remplacera toutes les méthodes logicielles actuelles.

Un shading plus intelligent
Le Mesh Shading : pour plus d’objets à l’écran
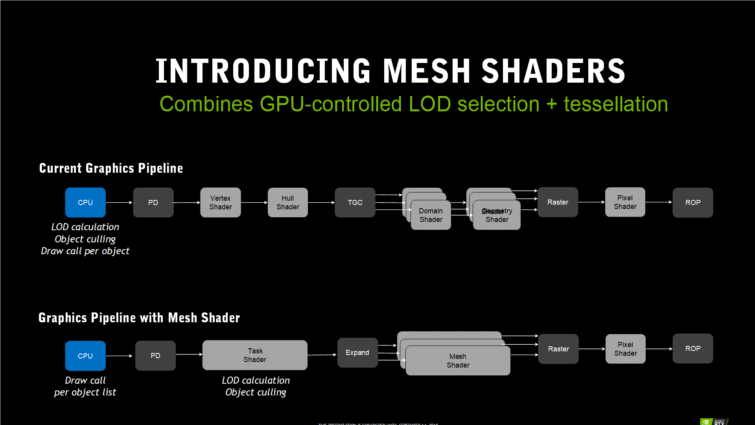
Outre les améliorations architecturales pures et dures de la puces, Turing s’accompagne aussi de technologies censées améliorer l’efficacité du rendu graphique. Ces techniques ne sont pas encore implémentées dans les jeux, et il faudra du temps pour en voir les bénéfices. Exemple type : le Mesh Shading, qui consiste à décharger le CPU de plusieurs tâches qui peuvent lui demander beaucoup de ressources lorsqu’il faut gérer la géométrie de centaines de milliers d’objets affichés à l’écran.
La technique semble fonctionner avec DirectX 11 et 12, et propose un shader spécial (mesh shader) pour prendre en charge par le GPU le calcul du LOD (niveau de détail à appliquer à l’objet par tesselation en fonction de sa distance dans la scène), et la suppression de l’objet dans le rendu lorsqu’il n’est pas visible à l’écran. Ce shader, moins spécifique que le vertex shader, peut prendre en charge une liste d’objets pour libérer le CPU en calculant directement sur le GPU la localisation de l’objet, son niveau de détail LOD et s’il peut être ignoré dans le rendu.
Variable Rate Shading : du shading astucieux
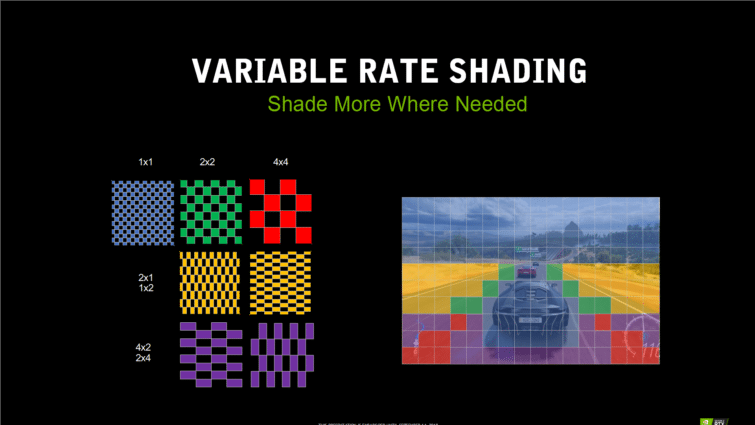
Turing va aussi permettre d’appliquer un shading différemment dans différentes parties de la scène à afficher, toujours dans le but d’améliorer les performances. Il est possible d’appliquer un shading exact en 1×1 pour chaque pixels, mais il sera aussi possible de réduire le nombre de pixels traités en appliquant des modèles moins précis (plus faible définition) sur d’autres parties de l’image, sur des blocs 2×1, 1×2, 2×2 et 4×4.

L’idée consiste évidemment à appliquer ce shading sans réduire la qualité de l’image finale. Le shading moins précis se fera en fonction du contenu de l’image (content-adaptive shading), par exemple à des aplats de couleur uniformes. La seconde idée consiste à appliquer un shading moins précis en fonction du mouvement des pixels (Motion-adaptive shading), par exemple à des parties de l’image où les mouvements sont très rapides (et donc flous).
NVIDIA a fait la démonstration de cette technique avec Wolfenstein II. Avec le Content-adaptive shading et le Motion-adaptive shading, les performances étaient annoncées 15 % meilleures, sans perte de qualité d’image visible à l’oeil nu. Il est possible que cette technique profite surtout aux cartes moins puissantes dans des jeux plus demandeurs en GPU, on parle alors de plus de 20 % de performances en plus autour de 60 ips…
Wolfenstein II fonctionne sous Vulkan, et ces techniques nécessitent des extensions dans l’API. On imagine que Microsoft prépare ces extensions pour DirectX avec NVIDIA.
La notion de RTX OPS : quel calcul ?
La notion de RTX-OPS est un petit bricolage mathématique qui consiste à donner une idée de la puissance de la carte en pratique dans un jeu avec ray tracing RTX en temps réel. Les GPU deviennent de plus en plus complexes, surtout avec Turing et ses différentes parties, pas toujours sollicitées de manière uniforme. Difficile alors de résumer ses performances simplement, c’est pourtant ce que l’indice RTX-OPS souhaite faire.

Le RTX-OPS est censé prendre en compte tous les différents coeurs du GPU pour montrer ses capacités globales : coeurs INT32, FP32, Tensor et RT. Il suppose donc qu’une applications ou un jeu utilise la totalité des coeurs du GPU. Evidemment, les premiers benchs des GeForce RTX que vous verrez sur le Web ne représenteront que les performances classiques du GPU, sans les coeurs RT et Tensor.
Voilà donc la méthode de calcul du RTX-OPS selon les estimations et constatations de fonctionnement pratique du GPU par NVIDIA :
- Les coeurs Tensor sont utilisés environ 20 % du temps de calcul de l’image (basé sur l’utilisation du DLSS)
- Les coeurs CUDA travaillent pour le reste du temps de calcul, soit 80 %
- Les coeurs RT sont utilisés pendant 50 % de ce temps de rendu restant (la moitié des 80 % restants, soit 40 %)
- Les pipelines INT32 sont utilisés pendant 35 % de ce temps de rendu restant (35 % de 80 %, soit 28 %)
- Un giga-ray prend l’équivalent de 10 TFLOPS de calcul sur CUDA (Pascal)
=> RTX-OPS = TENSOR x 20% + FP32 x 80% + RTOPS x 40% + INT32 x 28%
Pour une GeForce RTX 2080 Ti :
(14 FP32 TFLOPS x 80%) + (14 INT32 TIPS x 28%) + (100 RT TFLOPS x 40%) + (114 FP16 Tensor TFLOPS x 20%) = 78
| GeForce GTX 1070 | GeForce GTX 1080 | GeForce GTX 1080 Ti | GeForce RTX 2070 FE | GeForce RTX 2080 FE | GeForce RTX 2080 Ti FE | Quadro RTX 5000 | Quadro RTX 6000 | |
|---|---|---|---|---|---|---|---|---|
| RTX-OPS (Tera-OPS) | 6,5 | 8,9 | 11,3 | 45 | 60 | 78 | 62 | 84 |
C’est un peu tiré par les cheveux, mais ça se tient dans la mesure où il faut bien trouver un moyen d’afficher les performances relatives de chaque carte. Évidemment, nous n’utiliserons pas cet indice dans nos tests, qui resteront bien plus terre à terre : les performances de la carte en pratique !
NVLink : le renouveau du SLI ?
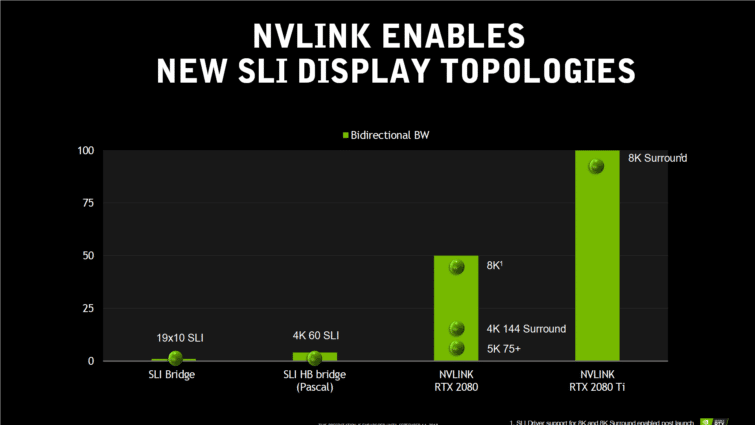
Les TU102 et TU104 sont les premiers GPU de bureau de Nvidia à utiliser le NVLink plutôt qu’une interface MIO (Multiple Input/Output) pour le support SLI. Le TU102 utilise deux liens x8, contre seulement un lien pour le TU104. Chaque liaison bidirectionnelle offre une bande passante pouvant atteindre 50 Go/s, dans chaque sens. Ainsi, la GeForce RTX 2080 Ti est capable d’atteindre 100 Go/s entre les cartes, là où la RTX 2080 est limitée à la moitié seulement.

Que ce soit avec un lien ou deux, du SLI de RTX ne fonctionnera qu’avec une paire de cartes espacées par trois ou quatre emplacements (au moins un emplacement vide entre les cartes est nécessaire pour le flux d’air). Officiellement, les GPU Pascal sont limités au même maximum de deux cartes, mais certaines configurations avec trois ou quatre GeForce GTX haut de gamme fonctionnant ensemble apparaissent parfois dans des benchmarks.
Une partie des problèmes rencontrés par le SLI sur Pascal venait des contraintes de bande passante entre les ponts SLI. Le lien MIO de l’interface SLI originale atteignait 1 Go/s, et l’implémentation sur Pascal poussait la bande passante à 4 Go/s environ. C’est suffisant pour renvoyer la trame de rendu de la seconde carte vers la première pour l’afficher sur un écran 4K à 60 Hz, mais cela devient insuffisant pour fonctionner à 120 Hz, une fréquence de rafraîchissement que de nombreux écrans haut de gamme atteignent aujourd’hui.
Même dans une configuration à liaison unique (50 Go/s), l’interface NVLink peut déplacer les données si rapidement que du SLI sur un écran 8K est possible. Piloter des moniteurs 4K à 144 Hz en mode Surround ne pose aucun problème, et deux liaisons x8 ont le débit nécessaire pour les écrans 8K en Surround.
La véritable question est plutôt : qui se soucie encore du SLI ? AMD et Nvidia ont tellement mis de côté les configurations multi-GPU que vous ne nous demandez quasiment jamais de résultats de benchs avec des configurations SLI. A une époque, il était commun de grouper deux cartes de milieu de gamme pour égaler les performances d’une carte plus puissante, mais Nvidia a mis un terme à cette pratique en limitant le support du SLI à ses modèles haut de gamme. Même la GeForce RTX 2070 n’a pas de connecteur NVLink. Les anciens jeux basés sur DirectX 11 fonctionnent toujours bien sur deux cartes, et une poignée de titres basés sur DirectX 12 exploitent le mode multi-GPU explicite de l’API. Mais le fait que des développeurs comme EA DICE consacrent du temps sur des fonctionnalités comme le ray tracing en temps réel et ignorent le multi-GPU en dit long sur l’avenir du SLI.
Des représentants de Nvidia nous ont expliqué qu’ils auraient prochainement d’autres choses à nous dire à ce sujet. Pour l’instant, le support du NVLink sur les GeForce RTX 2080 Ti et 2080 est une nouveauté qui nous permet de nous concentrer sur des taux d’images par seconde suffisant pour assurer un rendu fluide en 4K.
Du 8K en 60 Hz, VirtualLink pour la VR
Les cartes GeForce RTX Founders Edition comportent trois connecteurs DisplayPort 1.4a, une sortie HDMI 2.0b et une interface VirtualLink. Elles prennent en charge jusqu’à quatre moniteurs simultanément et sont bien entendu compatibles HDCP 2.2. Pourquoi pas de HDMI 2.1 ? NVIDIA nous répond que ce standard n’était pas encore prêt en novembre 2017, lorsque le design des cartes Turing devait être terminé.
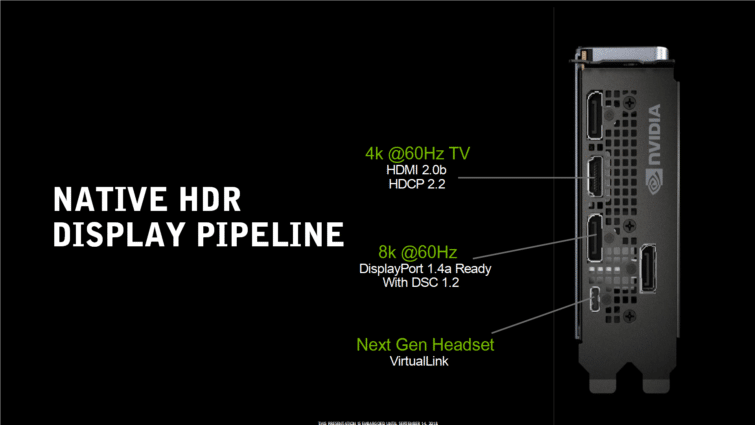
Turing permet également la compression de flux d’affichage (Display Stream Compression, ou DSC) via le DisplayPort, ce qui permet d’afficher du 8K (7680×4320) à 60 Hz, ou bien du 4K (3840×2160) HDR avec un taux de rafraîchissement de 120 Hz.
En parlant de HDR, Turing lit maintenant en natif le contenu HDR à l’aide d’un circuit de mappage tonal (tone mapping) dédié. Pascal de son côté avait besoin d’appliquer un traitement à part, ce qui ajoutait de la latence.

Enfin, les trois cartes Founders Edition incluent des connecteurs VirtualLink pour les casques VR de nouvelle génération. L’interface VirtualLink utilise un connecteur USB de type C mais avec un câblage différent permettant d’associer quatre lignes DisplayPort, un canal de données USB 3.1 Gen2 bidirectionnel pour les capteurs haute résolution, et jusqu’à 27W de puissance. Selon le consortium VirtualLink, les casques existants fonctionnent généralement avec une puissance de 15W (écrans, contrôleurs, audio, électronique du câble et pertes du câble et des connecteurs compris). Cette nouvelle interface est conçue pour prendre en charge les futurs appareils plus gourmands en énergie, avec des capacités d’affichage améliorées, un meilleur son et des caméras haut de gamme. Attention : la puissance fournie via VirtualLink n’est pas comprise dans le TDP annoncé des cartes GeForce RTX. Nvidia indique que l’utilisation de cette interface nécessite jusqu’à 35W supplémentaires.
Meilleur encodeur vidéo hardware
Turing s’équipe d’un nouveau moteur d’encodage et de décodage vidéo matériel, annoncé plus efficace dans tous les domaines. Le streaming étant devenu très important pour les joueurs, il fallait perfectionner l’encodage, ce qui est chose faite. NVIDIA annonce que son nouveau NVENC est capable d’encoder en temps réel une vidéo 8K HDR à 30 images par seconde. L’encodeur permettrait aussi d’économiser 25 % de débit en H.265 et 15 % en H.264, améliorant donc la qualité finale de l’image à débit égal. Pour la première fois, NVIDIA annonce surpasser la qualité d’encodage logiciel en x264 en mode Fast pour du temps réel.
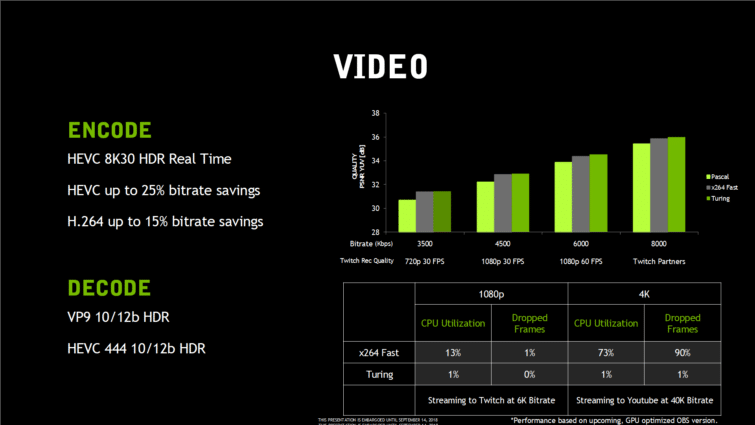
Côté décodage, NVENC est désormais capable de gérer le VP9 en 10 et 12 bits HDR, et le HEVC 4:4:4 10 et 12 bits HDR. Par rapport à Pascal, NVIDIA ajoute simplement le HEVC 4:4:4 en 12 bits.
Rénovation pour les cartes Founders Edition

Il faut dire adieu au blower avec ventilateur radial : les nouvelles cartes Founders Edition utilisent désormais une ventilation axiale à deux ventilateurs, sur un radiateur assez original encore jamais vu dans l’industrie des cartes graphiques. Ce radiateur est équipé d’une grande chambre à vapeur qui touche le GPU, mais aussi l’étage d’alimentation de la carte.

Attention, ce nouveau design signifie qu’il faudra désormais un boîtier bien ventilé pour prendre en charge tout l’air chaud que la carte va rejeter au sein même du PC (les ailettes étant axées sur la largeur de la carte, et pas la longueur). A n’en pas douter, les EOM vont devoir repenser l’aération de leur boîtier. Pour rappel, le blower était effectivement moins efficace en termes de refroidissement, et plus bruyant, mais il avait l’avantage de simplifier le design des PC par les fabricants. Certaines marques doivent faire un peu grise mine à la vue de ces Founders Edition, mais plusieurs fabricants ont déjà prévu des modèles blower classiques pour les satisfaire !

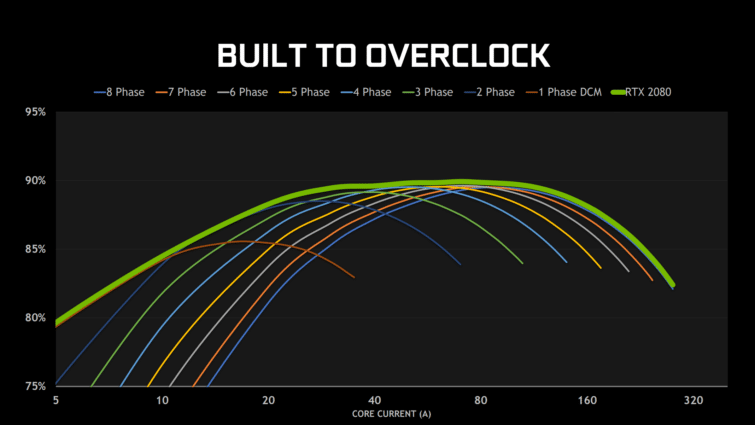
Les cartes Founders Edition semblent toutefois très travaillées pour taquiner les cartes haut de gamme des fabricants partenaires. Elles sont annoncées taillées pour l’overclocking, avec une limite de puissance qui peut monter 60 W au delà du standard de 260 W de la RTX 2080 Ti. Le rendement électrique est annoncé particulièrement travaillé grâce à un étage d’alimentation à huit phases, qui peuvent s’activer ou se désactiver dynamiquement en fonction de la charge.

NVIDIA scanner : overclocking automatique !
NVIDIA Scanner va permettre d’exploiter la technologie NVIDIA Boost à son maximum, en analysant les capacités de la carte graphique à monter en fréquence de manière stable, et en déterminant la fréquence d’overclocking maximale qu’elle peut atteindre. Chaque carte est certifiée pour tenir une fréquence minimale, mais certaines bénéficient d’un GPU de meilleur qualité (loterie du silicium !), ce qui permet de monter plus haut en fréquence sans planter.
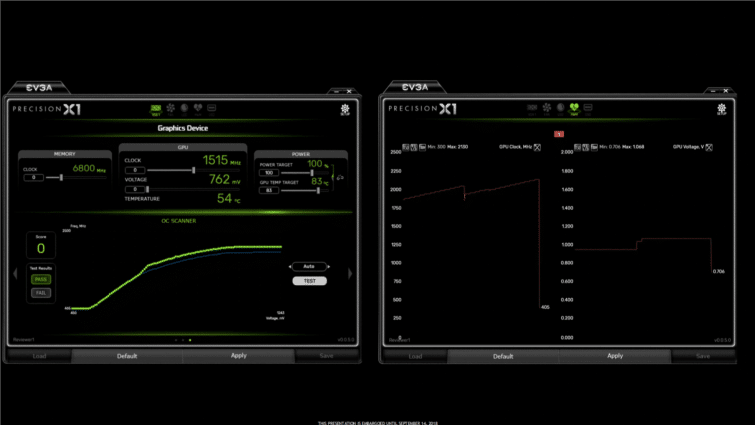
NVIDIA fournit un package API/DLL à ses partenaires, comme EVGA ou MSI, qui pourront implémenter cette fonction dans leur logiciel de gestion de la carte graphique. Le système fait tourner une routine arithmétique faite maison, qui peut gérer des erreurs (et les détecter) sans planter. De quoi donner au logiciel la capacité d’augmenter la tension pour tester la même fréquence. Une fois que le Scanner atteint la tension maximale et rencontre encore une erreur, une nouvelle courbe de fréquence et de tension est calculée sur la base des essais qui ont réussi. Le processus de test dure environ 20 minutes.
La bonne nouvelle, c’est que le Scanner ne sera pas limité aux GeForce RTX, et sera compatible avec les précédentes cartes graphiques. NVIDIA ne précise pas lesquelles, mais nous pensons qu’il s’agit uniquement de Pascal, dont la gestion du Boost est déjà très avancée. D’ailleurs, lors de la sortie des GeForce Pascal, NVIDIA nous avait fait la démonstration d’un outil très similaire, qui n’avait finalement jamais vu le jour…










