Attendue depuis de nombreux mois, l’architecture Ampere de NVIDIA a su garder ses principaux secrets cachés. Mais une fois les véritables caractéristiques de ces nouveaux GPU dévoilées, il apparaît clairement que cette nouvelle génération de chipsets graphiques représente un véritable point d’inflexion sur la feuille de route du constructeur.
Si Turing apportait pour la première fois l’accélération matérielle du ray-tracing et de l’IA au sein de produits grand public, Ampere offre une certaine maturité de ce côté, tout en améliorant les performances en matière de rastérisation classique.

Bien entendu, Ampere n’est pas une révolution en matière de rendu 3D, mais l’évolution par rapport à Turing, lancé en août 2018, est sensible. NVIDIA a su tirer le meilleur parti des technologies à sa disposition, de la meilleure finesse de gravure au type de mémoire graphique utilisée en passant par un système de refroidissement revu et amélioré. C’est donc l’occasion de faire un petit tour technique du propriétaire, avant de pouvoir d’ici quelques jours mesurer en pratique les performances des GeForce RTX 3070, RTX 3080 et RTX 3090.
L’histoire des cartes graphiques NVIDIA en images
Les GPU GA102 et GA104 en détail
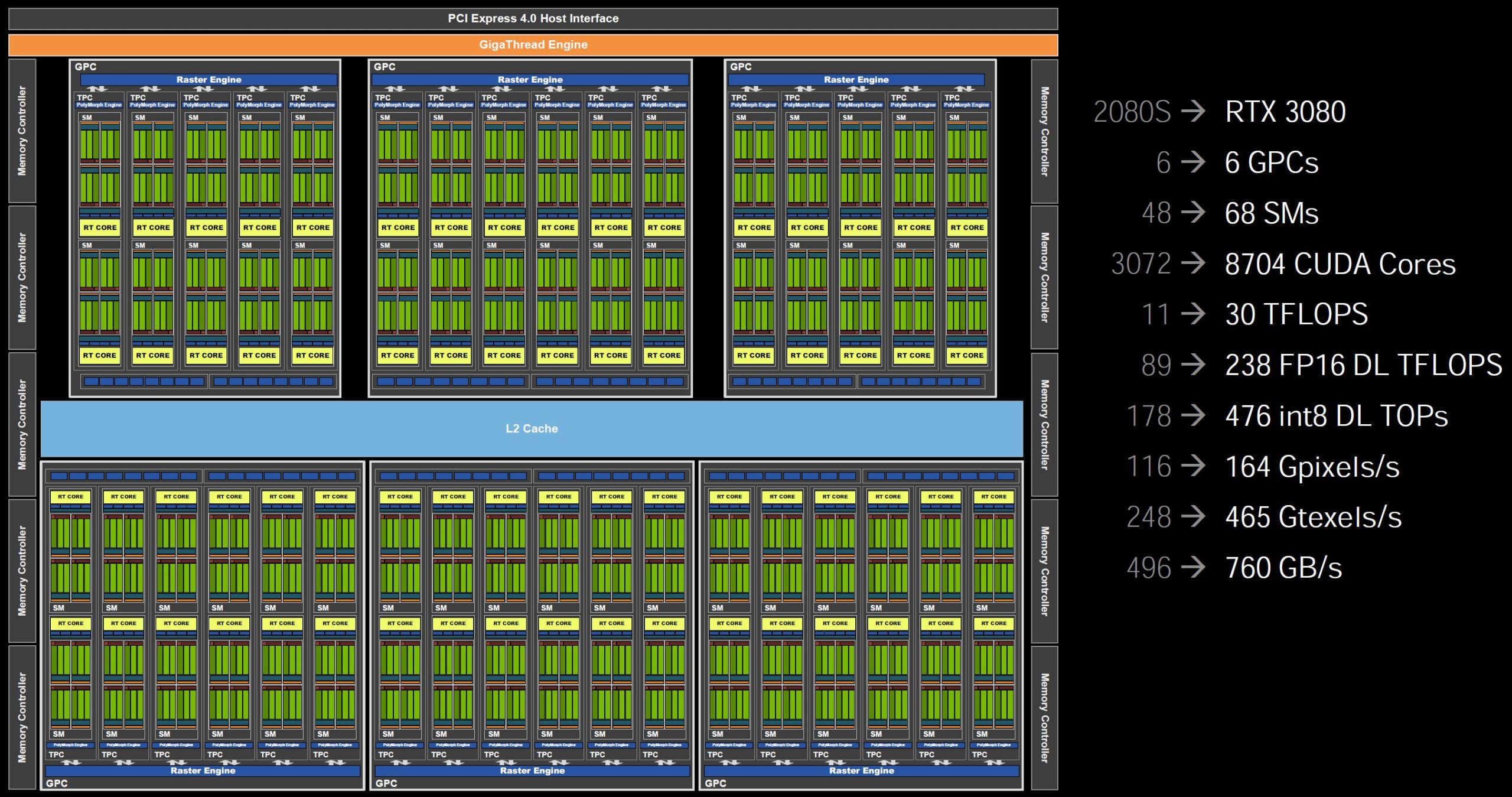
Si les GeForce RTX 3090 et RTX 3080 utilisent le même chipset graphique GA102, NVIDIA joue (entre autres) sur le nombre de GPC et de SM activés par GPU pour différencier les deux modèles. Ainsi, un chipset GA102 complet possède 7 GPC, chacun composé de 12 SM, pour un total de 10752 CUDA Cores. Mais deux SM sont désactivés sur la RTX 3090, ce qui porte le nombre total de SM à “seulement” 82 unités, soit 10496 CUDA Cores.

Sur la RTX 3080, c’est carrément un GPC entier qui est désactivé, et seuls quatre des 6 GPC restants possèdent leurs 12 SM actifs, les deux derniers n’en étant dotés que de 10. On arrive donc à un total de 68 SM et 8704 CUDA Cores pour cette carte graphique. De son côté, la RTX 3070 utilise un chipset GA104. On y trouve seulement 4 GPC et 46 SM actifs, soit 5888 CUDA Cores fonctionnels.
D’autres variables d’ajustement sont utilisées par NVIDIA pour segmenter son offre : fréquences de fonctionnement de base et Boost, nombre de RT et de Tensor Cores ou encore type (GDDR6 sur la RTX 3070, GDDR6X sur les deux autres modèles), vitesse et quantité de mémoire graphique utilisée. Le tableau ci-dessous regroupe toutes les données techniques des différents GPU, permettant une comparaison rapide entre chaque modèle.
| Modèle | GeForce RTX 3090 | GeForce RTX 3080 | GeForce RTX 3070 | GeForce RTX 2080 Ti | GeForce RTX 2080 Super |
|---|---|---|---|---|---|
| Architecture GPU | Ampere GA102-300 | Ampere GA102-200 | Ampere GA104-300 | Turing TU102-300A | Turing TU104-450 |
| Gravure | 8 nm (Samsung) | 8 nm (Samsung) | 8 nm (Samsung) | 12 nm FFN | 12 nm FFN |
| Taille du die | 628 mm² | 628 mm² | 395 mm² | 754 mm² | 545 mm² |
| Transistors | 28 milliards | 28 milliards | 17,4 milliards | 18,6 milliards | 13,6 milliards |
| GPCs | 7 | 6 | 4 | 6 | 6 |
| SMs | 82 | 68 | 46 | 68 | 48 |
| CUDA Cores | 10496 | 8704 | 5888 | 4352 | 3072 |
| Tensor Cores | 328 | 272 | 184 | 544 | 384 |
| RT Cores | 82 | 68 | 46 | 68 | 48 |
| Fréquence GPU Base (Boost) | 1395 MHz 1695 MHz | 1440 MHz 1710 MHz | 1500 MHz 1730 MHz | 1350 MHz 1545 MHz | 1650 MHz 1815 MHz |
| FP32 TFLOPS | 35,6 | 29,8 | 20,3 | 13,5 | 11,1 |
| FP16 TFLOPS | 35,6 | 29,8 | 20,3 | 26,9 | 22,3 |
| Tensor TFLOPS (FP16) | 285 | 238 | 163 | 108 | 89 |
| RT TFLOPS | 69 | 58 | 40 | 34 | |
| Mémoire | 24 Go GDDR6X | 10 Go GDDR6X | 8 Go GDDR6 | 11 Go GDDR6 | 8 Go GDDR6 |
| Interface Mémoire | 384-bit | 320-bit | 256-bit | 352-bit | 256-bit |
| Vitesse de transfert | 19,5 Gb/s | 19 Gbps | 14 Gb/s | 14 Gb/s | |
| Bande Passante VRAM | 936 Go/s | 760 Go/s | 448 Go/s | 616 Go/s | 496 Go/s |
| ROPs | 128 | 80 | 64 | 88 | 64 |
| Unités de texture (TMUs) | 656 | 544 | 368 | 272 | 192 |
| Texel Fill-rate (Gigatexels/s) | 556 | 465 | 317 | 420 | 248 |
| Cache L1 par SM | 128 Ko | 128 Ko | 128 Ko | 64 Ko | 64 Ko |
| Cache L2 | 6 Mo | 5 Mo | 4 Mo | 5,5 Mo | 4 Mo |
| TDP | 350 W | 320 W | 220 W | 260 W | 250 W |
RTX 3070, 3080 et 3090 : NVIDIA accélérera aussi le chargement des jeux sur les RTX 2080
Des Streaming Multiprocessors améliorés
Les Streaming Multiprocessors ont été améliorés depuis Turing, alors qu’ils avaient déjà profité d’optimisations par rapport à Pascal. On est en effet passé de quatre groupes de 32 unités capables de calculer en FP32 ou en INT32 avec Pascal, à quatre groupes de 16 unités FP32 associées à 16 autres unités INT32 avec Turing. La nouveauté était que ces unités de calcul pouvaient fonctionner de manière concurrentielle.

Ampere va encore plus loin de ce côté : désormais chaque SM regroupe 4 clusters de 32 unités de calcul, mais chaque cluster comprend 16 unités pouvant prendre en charge des calculs en FP32 ou INT32, et 16 unités exclusivement dédiées aux calculs FP32. Ces deux groupes peuvent travailler de manière concurrentielle via des datapaths distincts. De manière idéale, chaque SM peut donc traiter simultanément 64 instructions INT32 et 64 instructions FP32, ou bien 128 instructions FP32, soit le double des SM de Turing. NVIDIA a également apporté quelques améliorations du côté du cache L1, qui passe de 64 Ko par SM sur Turing à 128 Ko par SM sur Ampere.
On pourrait craindre que le doublement des unités FP32 seulement, et pas celui des unités de calcul INT32, aboutisse à un déséquilibre en matière de charge de travail, mais il n’en est en réalité rien : c’est justement une répartition similaire entre calculs FP32 et INT32 que l’on retrouve dans une majorité de jeux vidéo.
Des Tensor Cores et des RT Cores plus efficaces
Introduits par NVIDIA avec l’architecture Volta puis démocratisés auprès des joueurs avec Turing, les Tensor Cores sont chargés de calculs moins précis que ceux en FP32 ou INT32. NVIDIA les utilise pour sa technologie DLSS, et plus globalement pour tout ce qui se rapport à l’intelligence artificielle.
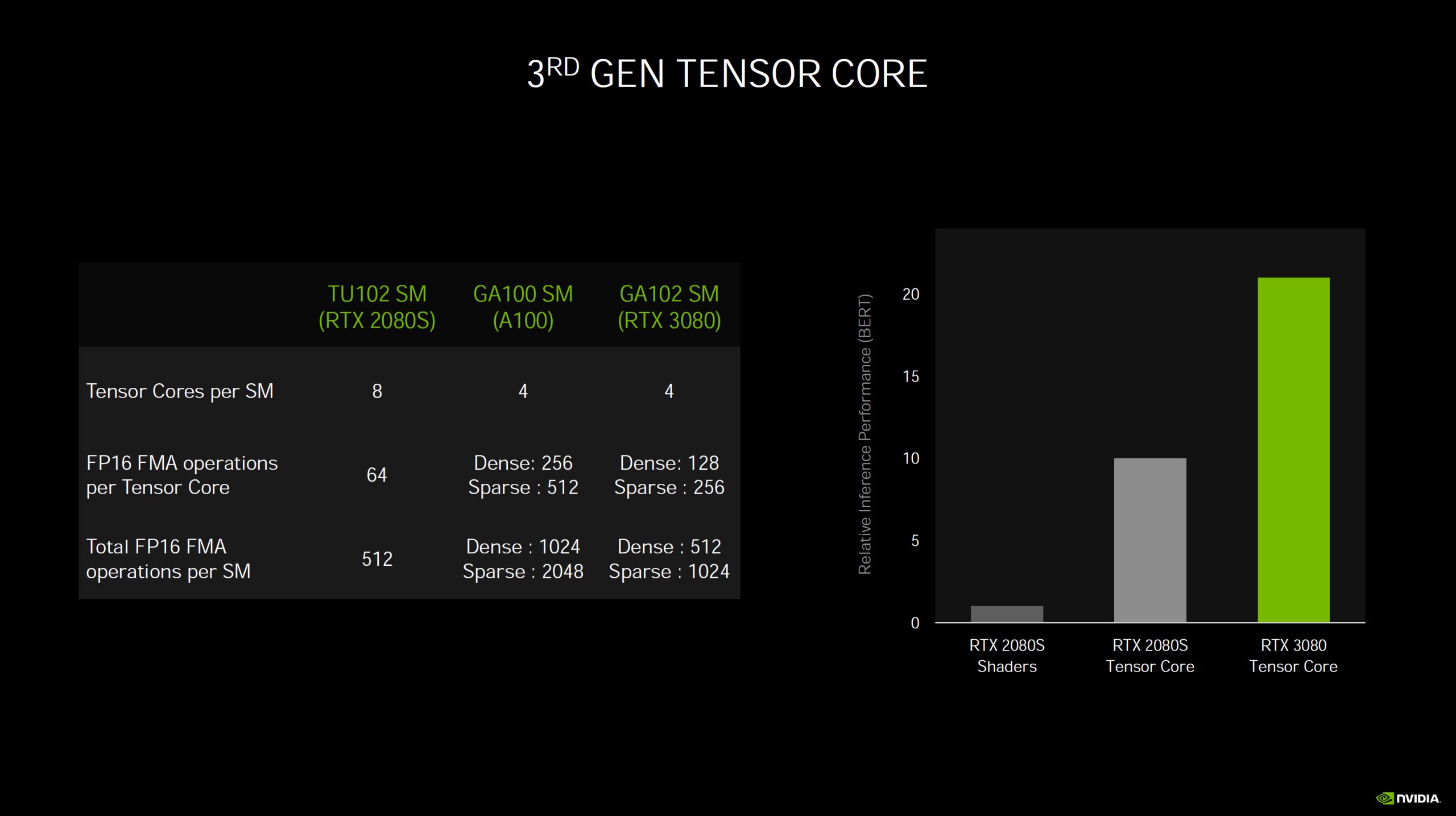
Avec Ampere, l’efficacité de ces Tensor Cores de troisième génération est multipliée par quatre avec des matrices denses, et par huit avec des matrices creuses (c’est-à-dire contenant beaucoup de zéros). Cette amélioration de l’efficacité des Tensor Cores permet à NVIDIA d’en diminuer par deux leur nombre par GPU, tout en affichant en même temps une puissance de calcul multipliée par deux ou par quatre suivant le type de matrice !
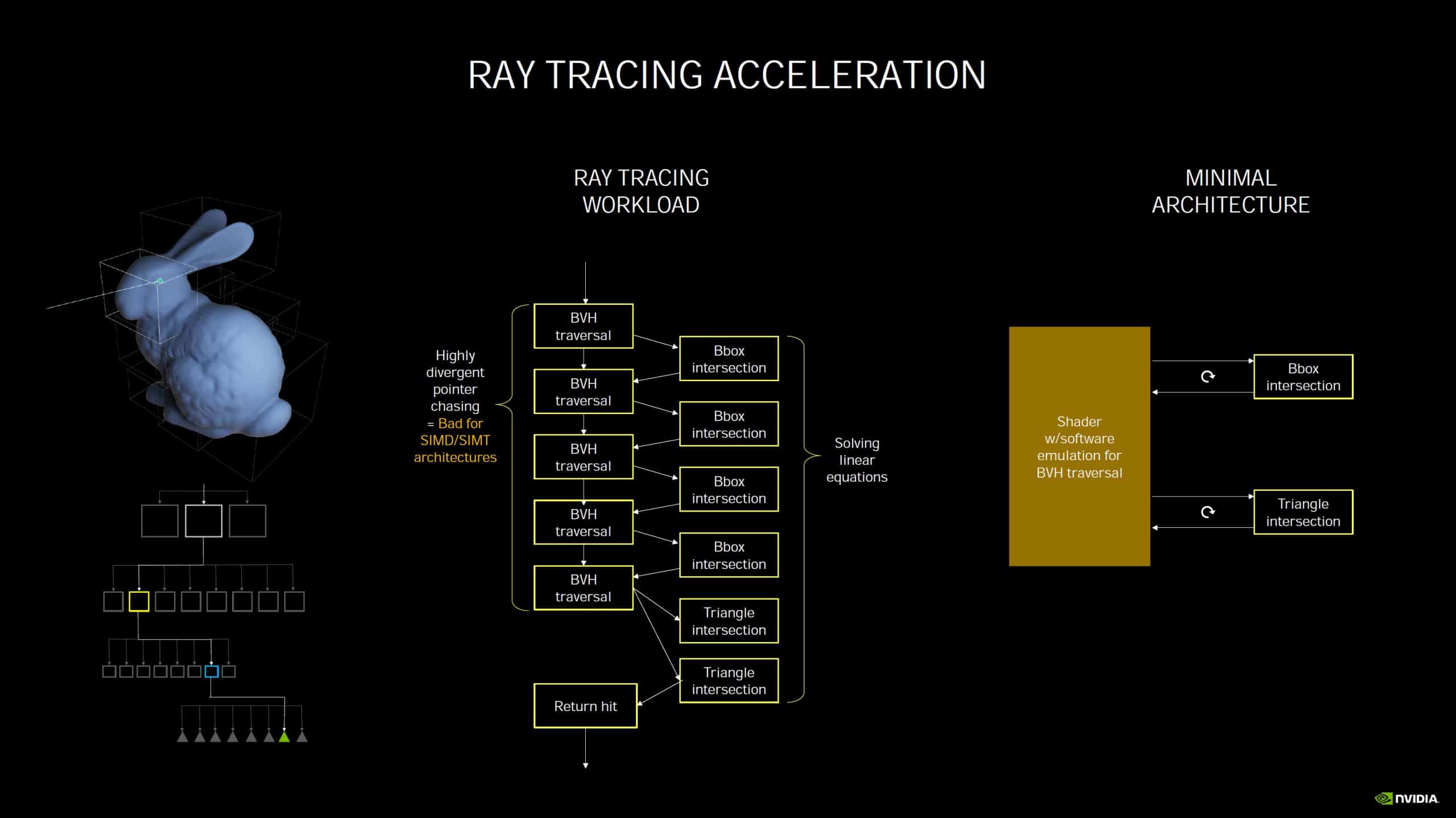
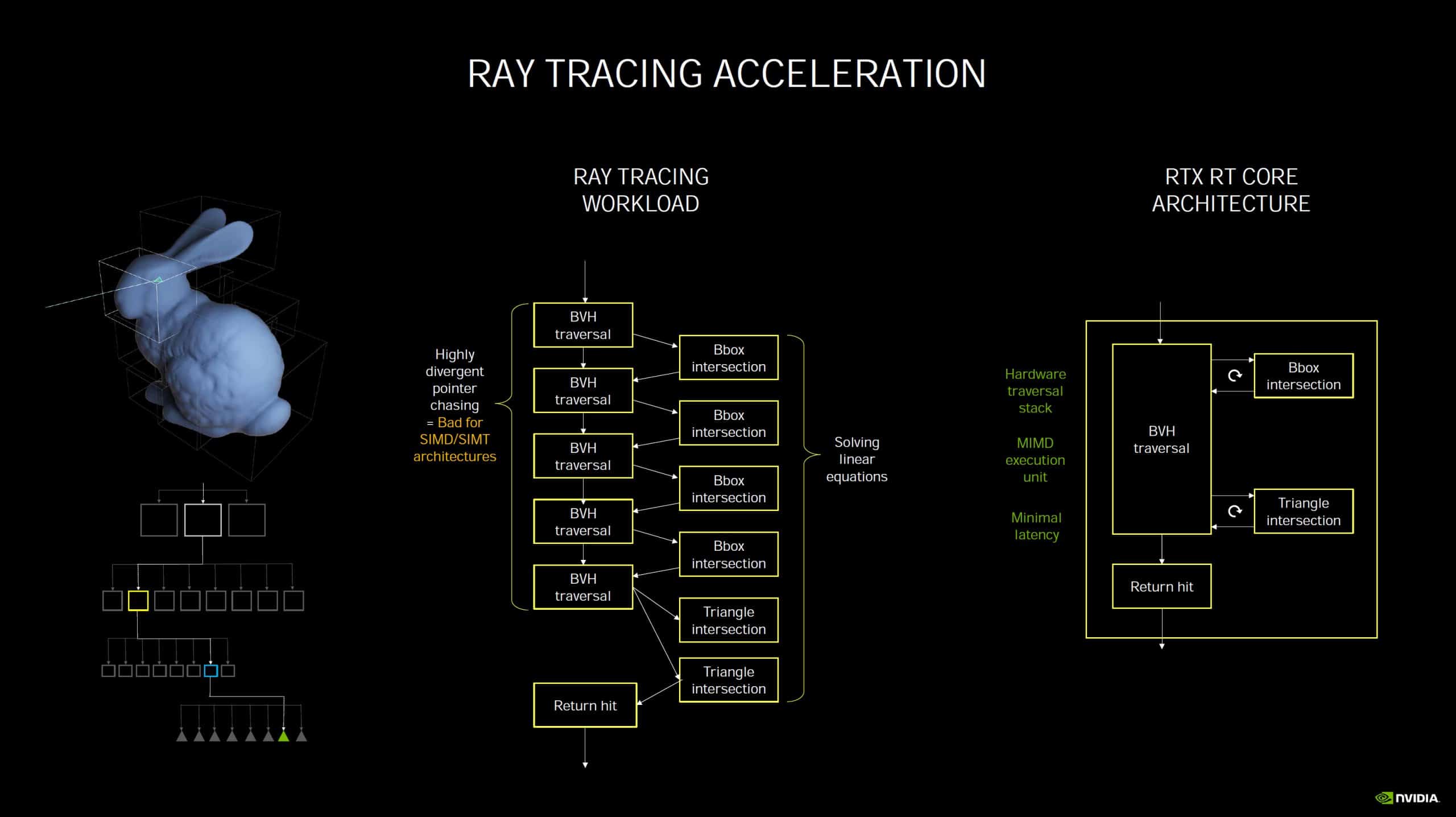
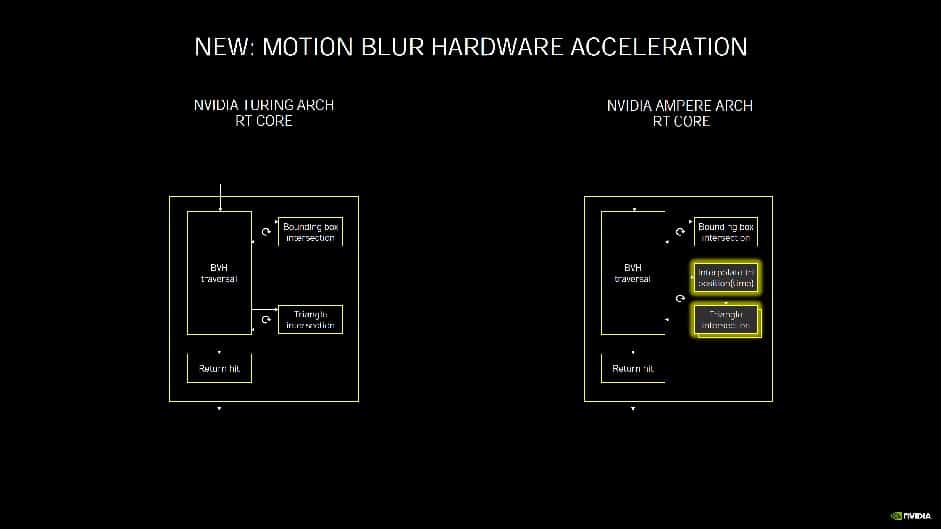
Du côté des RT Cores, chargés des calculs dédiés au lancer de rayons (ou ray tracing), NVIDIA indique simplement que la deuxième génération intégrée à Ampere est plus efficace, mais sans donner plus de détails. On notera tout de même qu’ils sont désormais capables d’accélérer les calculs lorsqu’un effet de flou de mouvement est appliqué. En pratique et dans ce cas précis, le rendu peut être jusqu’à huit fois plus rapide. On attend d’autant plus impatiemment les premiers benchmarks indépendants des nouvelles RTX 3070, RTX 3080 et RTX 3090…
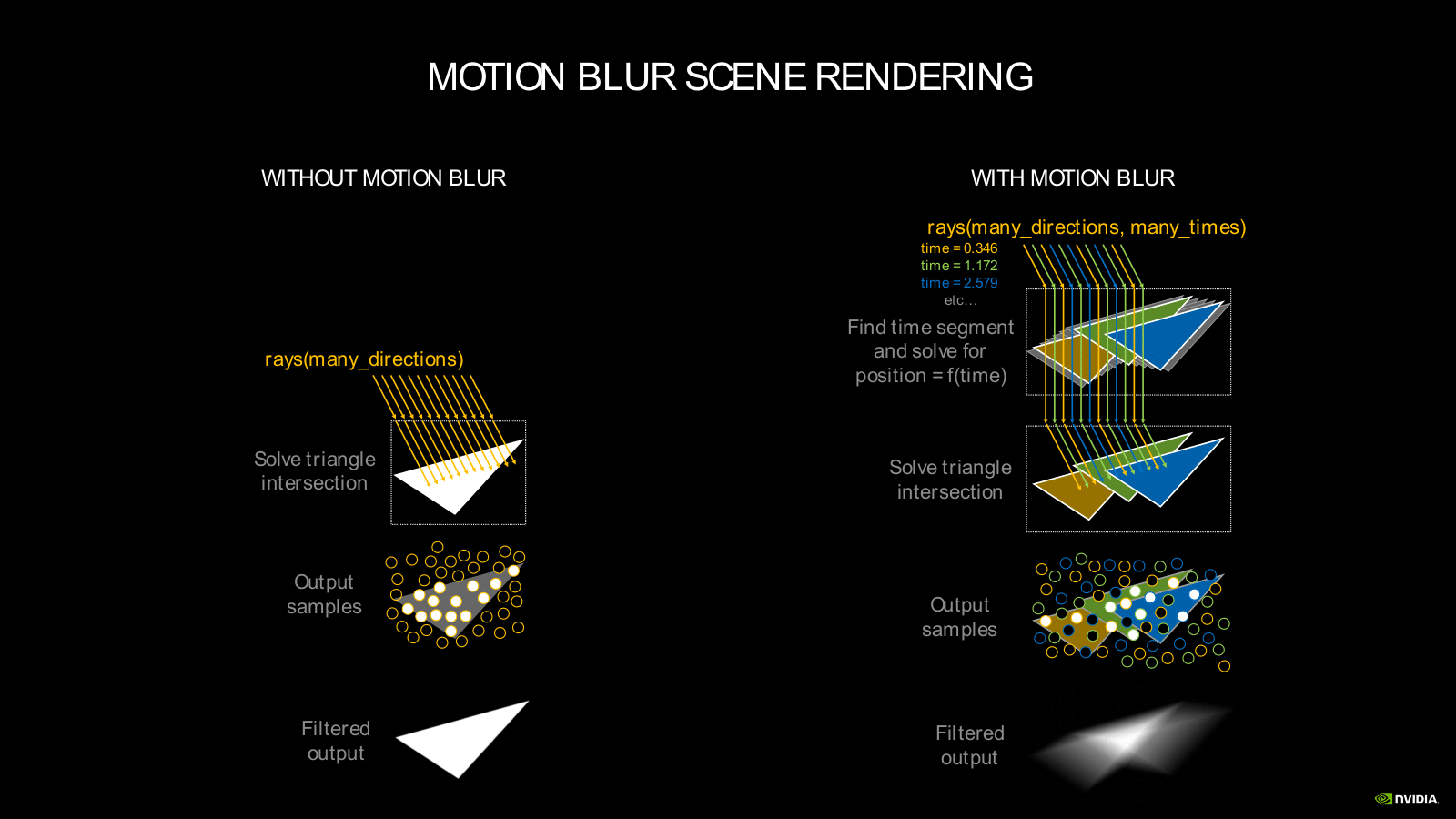
Cette nouvelle fonctionnalité peut être utilisée dans les jeux et le rendu 3D en temps réel, mais également dans les applications de rendu 3D comme Blender. De manière globale, le rendu en ray tracing dans les applications 3D est deux fois plus rapide sur une RTX 3080 qu’avec une RTX 2080 Super.
De la mémoire GDDR6X particulièrement rapide
Si la GeForce RTX 3070 utilise toujours de la mémoire GDDR6, les GeForce RTX 3080 et RTX 3090 bénéficient de leur côté de mémoire GDDR6X. Un ensemble d’améliorations et d’optimisations, par exemple une modulation du signal PAM4 (4-level Pulse Amplitude Modulation, avec un signal entre le GPU et la mémoire qui utilise quatre niveaux de tension différents pour encoder deux bits par cycle d’horloge) en plus du mode RDQS classique, permet à ce type de mémoire de se montrer particulièrement rapide, NVIDIA n’hésitant pas à la présenter comme la mémoire graphique la plus rapide du marché.
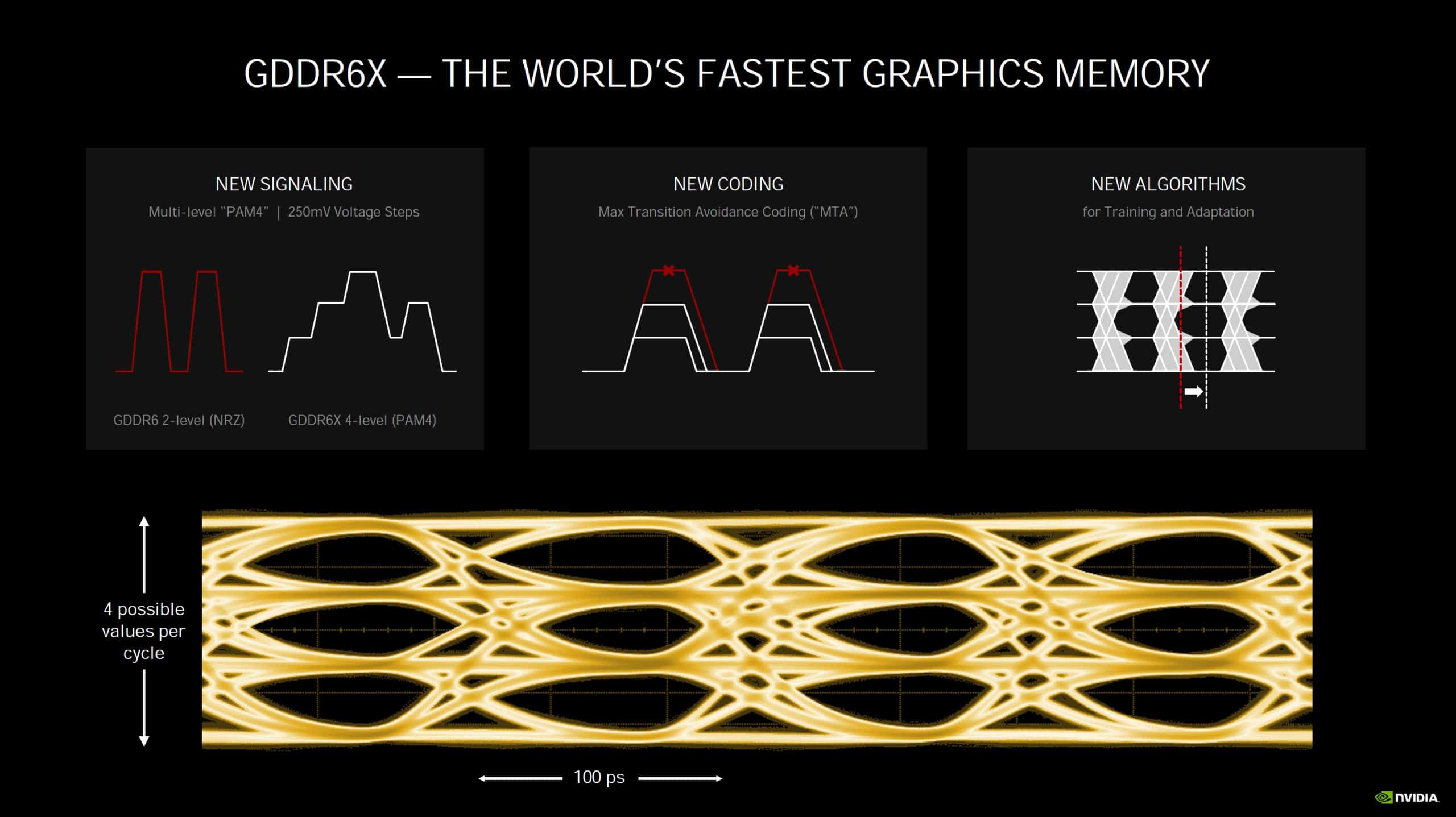
Pour ses GeForce RTX 3080 et RTX 3090, NVIDIA utilise des puces de mémoire GDDR6X fabriquées par Micron. Celle-ci atteint 19 Gbps par broche sur la 3080, et même 19,5 Gbps sur la 3090. À titre de comparaison, les vitesses actuellement atteintes par de la mémoire GDDR6 sont de l’ordre de 14 à 16 Gbps. En tenant compte de leur bus respectifs (320-bit et 384-bit), on arrive à une bande passante mémoire de 760 Go/s sur la RTX 3080 et 936 Go/s sur la RTX 3090.
La tension appliquée étant en revanche identique entre la GDDR6 et la GDDR6X (VDD et VDDQ de 1,25-1,35V, VPP de 1,8V), il ne devrait pas y avoir de différence sensible au niveau de la consommation. Au contraire même : Micron explique que la mémoire GDDR6X permet de réduire de 15% la consommation par bit transféré, par rapport à de la mémoire GDDR6.
La 4K démocratisée, la 8K à 60 Hz avec ray-tracing grâce au DLSS
Avec Ampere et sa puissance de calcul vertigineuse, NVIDIA ne vise plus seulement la 4K : c’est directement la 8K qui est en ligne de mire. C’est d’ailleurs pour cette raison que les nouvelles GeForce RTX 3070, RTX 3080 et RTX 3090 sont dotées de sorties HDMI 2.1 offrant une bande passante de 48 Gbps : c’est suffisant pour n’utiliser qu’un seul câble avec un écran 8K à 60 Hz.

La technologie DLSS 2.1 (oui, le SDK DLSS a récemment été mis à jour en version 2.1, apportant quelques nouveautés par rapport au DLSS 2.0) est particulièrement utile ici, NVIDIA introduisant un nouveau mode 8K rendu possible grâce à une amélioration du modèle mathématique utilisé en matière d’analyse spatiale. Cette “Super Resolution” permet d’obtenir un rendu final en 8K à partir d’une image calculée en 2560 x 1400, ce qui représente un upscaling intelligent de x9 ! Pour rappel, le mode Performances du DLSS permettait d’appliquer un upscaling de x4 “seulement” afin de passer d’un rendu Full HD à une image 4K…
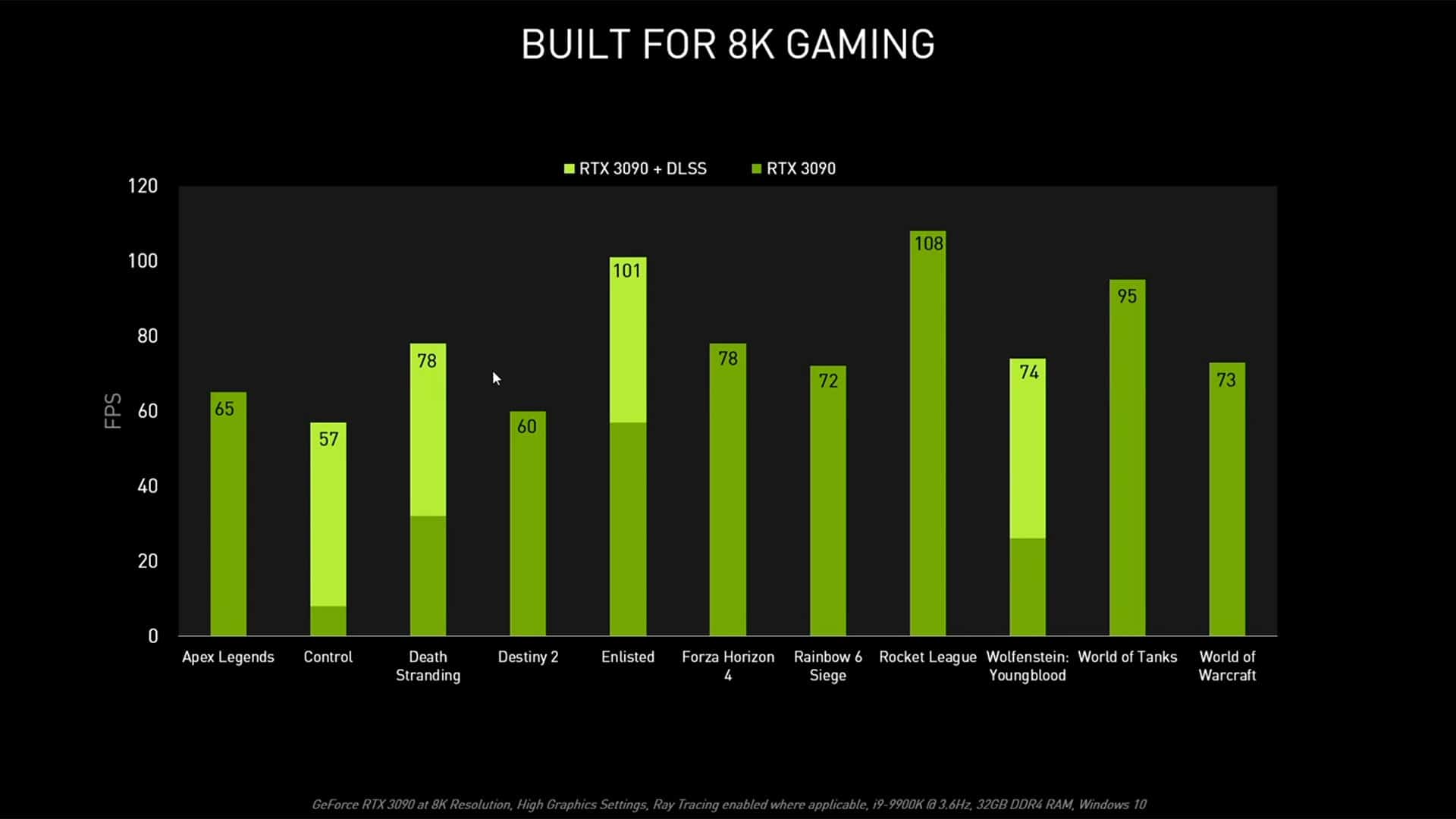
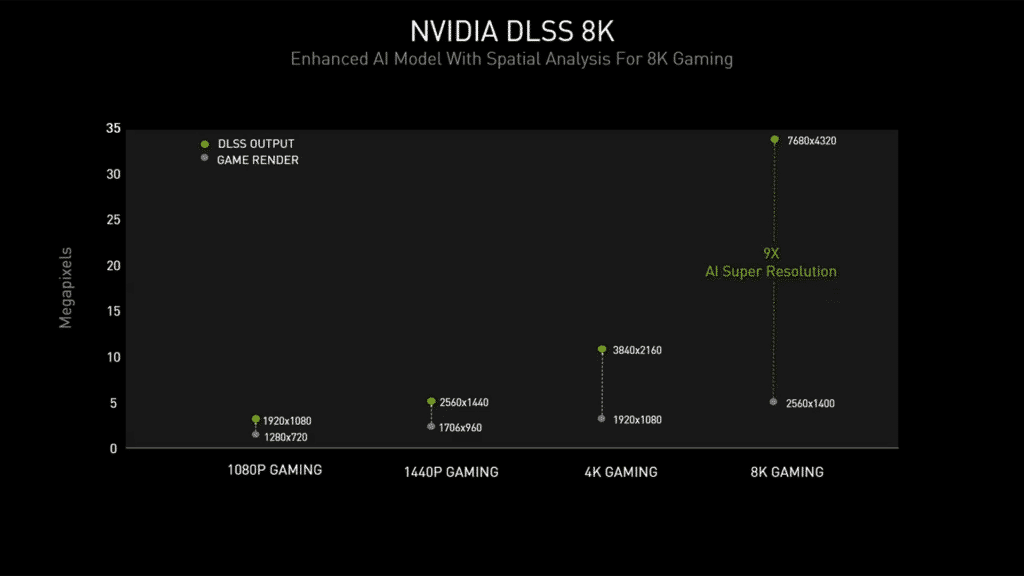
En termes de performances, il devient dès lors possible de jouer en 8K de manière fluide (c’est-à-dire avec un framerate moyen supérieur à 60 FPS) à de nombreux jeux actuels avec une RTX 3090 : Apex Legends, Destiny 2 ou encore Death Stranding pour ne citer qu’eux. Rappelez-vous qu’une image 8K possède 16 fois plus de pixels qu’une image Full HD !
Exclusif : premier décryptage complet de la techno DLSS de NVIDIA !
Encodage et décodage vidéo : l’avènement du codec AV1
Si le moteur de compression NVENC d’Ampere est identique à celui embarqué dans Turing, celui de décompression prend désormais en charge le codec AV1. Ce successeur du VP9 et du HEVC commence à être utilisé sur Vimeo et YouTube (en version bêta) avec certains contenus, tandis que Netflix l’a choisi pour les flux vidéo envoyés sur les terminaux mobiles. Il faut dire qu’avec un taux de compression 30 % à 40 % plus élevé que l’HEVC ou le VP9, y compris sur les vidéos 4K, le codec AV1 est une aubaine pour les plateformes de streaming.
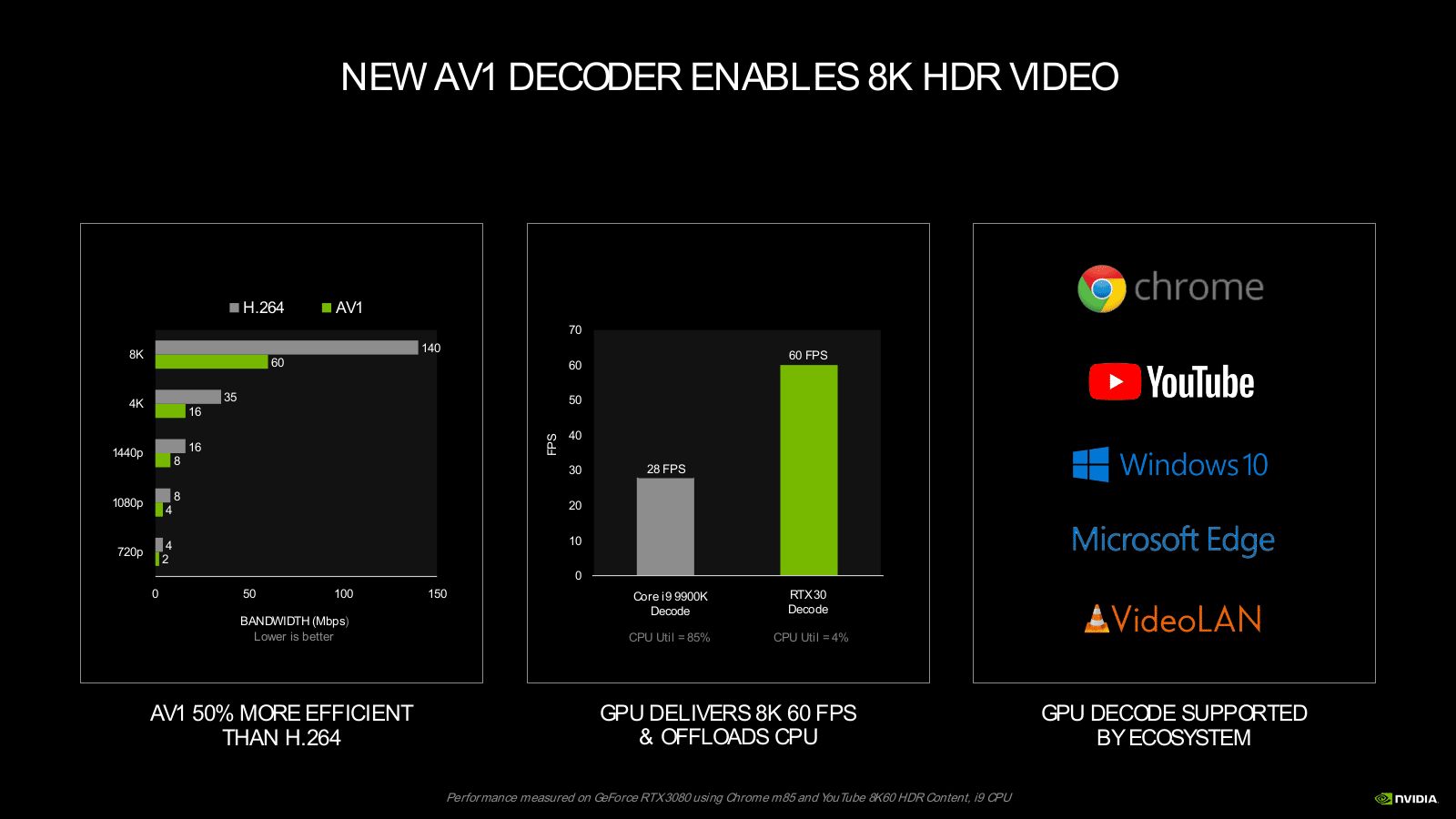
On peut donc supposer que ce codec va peu à peu se démocratiser, et pourquoi pas remplacer à terme le VP9 et les H.264/H.265. La prise en charge matérielle de sa décompression est tout à fait pertinente avec les nouvelles GeForce RTX Ampere : ce codec particulièrement efficace est taillé pour la 8K HDR.
En résumé
“L’âge de la maturité”, l’expression est galvaudée et déclinée à toutes les sauces, mais il paraît difficile de mieux résumer le positionnement de l’architecture Ampere par rapport à la génération antérieure. Deux ans après Turing, NVIDIA semble en effet avoir amélioré, sinon optimisé, tous les aspects techniques de son GPU avec ses RTX 30. La finesse de gravure, en premier lieu, avec un procédé 8 nm en lieu et place du 12 nm des RTX 20. Le nombre de transistors grimpe en flèche en conséquence, la taille du die se réduit par rapport aux plus grands mastodontes de la génération précédente et les puces comprennent davantage de GPC, SM et CUDA Core. Les Streaming Multiprocessors, justement, gagnent en efficacité et traitent, en résumé, le double des instructions FP32 des SM de Turing, avec un cache L1 lui aussi doublé. Du côté de la mémoire, on bascule vers la GDDR6X pour les deux têtes de gondole, les RTX 3090 et 3080, avec un ensemble d’optimisations qui dopent la bande passante … sans parler de quantités de VRAM jusqu’alors inexplorées dans cette gamme – 24 Go pour la RTX 3090 contre moins de la moitié pour la pourtant surpuissante RTX 2080 Ti.
Mais c’est évidemment au niveau des technologies les plus modernes et récentes, à savoir les Tensor Core introduits avec l’architecture Volta puis les RT Core de la génération Turing, qu’Ampere fait le plus grand bond. Meilleure exploitation de l’intelligence artificielle, en particulier pour la technologie DLSS, rendu amélioré du ray tracing (jusqu’à deux fois supérieur, sur une RTX 3080 face à une RTX 2080 Super !) notamment avec les effets de flou de mouvement… NVIDIA évoque, globalement, des puissances de calcul débridées, dans ces domaines plus que jamais sous les feux des projecteurs avec l’arrivée imminente des consoles next-gen. Avec la promesse, in fine, de concrétiser le jeu 8K de manière fluide … là où les futures consoles de salon, supposément proposées à des prix encore jamais atteints, ne tutoieront “que” la 4K. Il y a donc de quoi se réjouir, tout du moins dans un premier temps sur le plan théorique. Place désormais à la réalité du terrain, avec les tests qui ne devraient plus tarder !










Je me pose la question de la feuille de route… Ils en ont une pour les GTX et Ti sur les RTX ?
Est-ce que ça vaut le coup de patienter?
Les RTX3090 sont vraiment intéressantes pour le calcul GPu, mais du coup je me pose la question de l’investissement…
S’il me faut attendre une paire de mois et obtenir du Ti et du GTX… why not?