L’entreprise a également conclu un partenariat avec SiPearl pour équiper des supercalculateurs européens d’accélérateurs Ponte Vecchio.
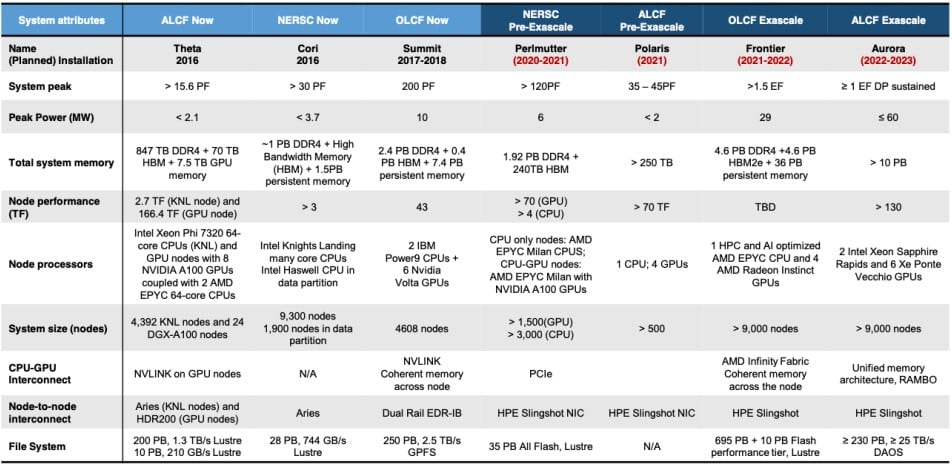
Le supercalculateur Aurora de l’Argonne National Laboratory devait être le premier à franchir la barre de l’exaflops LINPACK. Cependant, sa mise en ligne a été retardée à cause des difficultés rencontrées par Intel avec son nœud de gravure en 7 nm, désormais appelé Intel 4. En conséquence, Aurora s’est fait devancer par le supercalculateur Frontier ; ce dernier s’appuie sur des processeurs AMD EPYC personnalisés et de processeurs graphiques Radeon Instinct. Pour se consoler, Intel a pu revoir ses prévisions de performance à la hausse. En effet, la société table maintenant sur 2 exaflops.

Cet ajustement se justifie par de meilleures performances qu’escompté pour les GPU Ponte Vecchio. Ces derniers, épaulés par les processeurs Sapphire Rapids, sont au cœur du supercalculateur. Or, Intel a désormais une meilleure idée des performances de ces deux solutions. En conséquence, la société projette désormais 2 exaflops FP64 (Rpeak) pour Aurora. Intel estime qu’une telle puissance sera mise en ligne en début d’année 2023. Notez que cette période doit coïncider avec la livraison d’El Capitan. Celui-ci promet également 2 exaflops de puissance de traitement en double précision ; la primeur du supercalculateur Aurora à cette échelle reste donc incertaine.
NVIDIA présente le supercalculateur Cambridge-1, le plus puissant du Royaume-Uni
Des GPU Ponte Vecchio plus performants que prévu
Pour mémoire, la première évocation d’Aurora remonte à 2015. À l’époque, il était censé s’appuyer sur des accélérateurs Xeon Phi pour des performances d’environ 180 pétaflops à l’horizon 2018. Finalement, Intel avait abandonné les Xeon Phi et renégocié les contrats avec l’Argonne National Laboratory. L’accord portait sur une mise en ligne d’un système atteignant l’exaflops cette année ; un délai non respecté pour les raisons mentionnées ci-dessus.
Concernant les GPU Ponte Vecchio, ces puces associent différents types de tiles et leur fabrication implique plusieurs nœuds de gravure. Au départ, les 16 tiles dédiées au calcul devaient être gravées en 7 nm ; désormais, après maints rebondissements, comme l’hypothèse d’une gravure en 7 nm par TSMC, ces tiles profitent du processus N5 (5 nm) de TSMC dans un premier temps, puis de l’Intel 4 ensuite. Logiquement, cette finesse de gravure plus avancée a des répercussions sur les performances : cette dernière mouture de Ponte Vecchio est meilleure que la version initialement imaginée par Intel. Nous ne connaissons pas tous les changements, mais on peut supposer que le N5 autorise une densité d’unités de calcul supérieure par exemple.

Pat Gelsinger résume : “En ce qui concerne l’amélioration à 2 ExaFLOPS contre 1 ExaFLOPS, c’est en grande partie grâce à Ponte Vecchio, le cœur du système, qui dépasse les jalons contractuels initiaux. Ainsi, lorsque nous l’avons configuré pour avoir un certain nombre de processeurs […] nous avons essentiellement surévalué le nombre de sockets nécessaires pour dépasser confortablement 1 exaflops. Du fait que Ponte Vecchio dépasse largement les objectifs de performance initiaux, nous sommes maintenant confortablement au-dessus de 2 ExaFLOPS […]“.

Partenariat avec SiPearl
Bien sûr, les accélérateurs Ponte Vecchio équiperont d’autres supercalculateurs à l’avenir, notamment européens. SiPearl, concepteur du microprocesseur qui sera au cœur de plusieurs supercalculateurs européens, a d’ailleurs officialisé sa collaboration avec Intel. Celle-ci vise à “favoriser le déploiement du supercalcul exascale en Europe”.
Les deux partenaires vont ainsi donner à leurs clients européens l’opportunité de combiner Rhea, le microprocesseur développé par SiPearl, et Ponte Vecchio, l’accélérateur d’Intel, afin de constituer un nœud de calcul à haute performance. Pour permettre cette combinaison, SiPearl utilisera oneAPI, l’interface de programmation ouverte et unifiée créée par Intel. Précisons que Rhea est un SoC gravé en 6 nm par TSMC qui comporte jusqu’à 72 cœurs Arm Neoverse Zeus.
Jeff McVeigh, Vice-président d’Intel et Directeur Général de sa division Super Compute, s’est exprimé à ce sujet en ces termes : “Nous sommes ravis que Ponte Vecchio, basé sur l’architecture Intel Xe HPC, ait été sélectionné par SiPearl comme accélérateur de calcul haute performance pour équiper les premiers supercalculateurs exascale d’Europe. Intel est fier d’accompagner SiPearl dans l’adoption de l’interface de programmation unifiée oneAPI afin d’accroître la productivité des développeurs. Alors que nous mettons en œuvre notre stratégie IDM 2.0 pour apporter des technologies de pointe à nos partenaires européens, nous voyons un grand potentiel dans notre travail avec SiPearl”.
Enthousiasme partagé par Philippe Notton, président et fondateur de SiPearl : “Nous nous félicitons de cette collaboration avec Intel, dont l’accélérateur Ponte Vecchio, optimisé pour le calcul haute performance, est extrêmement innovant. L’association de Rhea, le microprocesseur européen haute performance que nous concevons, avec l’accélérateur Ponte Vecchio d’Intel en utilisant l’interface de programmation oneAPI, va nous permettre de développer rapidement des nœuds de calcul hétérogènes pour répondre aux besoins du supercalcul exascale européen”.
Le nombre de supercalculateurs AMD dans la liste TOP500 a plus que doublé en 6 mois
Cap sur le zettascale
Enfin, Intel évoque déjà l’informatique zettascale (un zettaflops vaut 1021 flops ; un exaflops, 1018 flops). L’entreprise estime qu’elle parviendra à atteindre ce stade en 2027. Cependant, elle ne précise pas ses plans. En tout cas, l’objectif s’annonce ambitieux. Il consiste à multiplier par 1000 les performances de calculs HPC en 5 ans ; il en a fallu une douzaine pour passer du petascale à l’exascale.
Sources : Tom’s Hardware US, NextPlatform, Communiqué de presse SiPearl











